Torna alla pagina di Algoritmi e strutture dati
Questa pagina è stata aggiornata GRAZIE agli appunti che AVETE INVIATO nel periodo di chiusura della sezione UniCrema!! È SERVITA A QUALCOSA, NO?! ;)
:: Algoritmi e strutture dati - Algoritmi di ordinamento ::
Algoritmo Insertion-Sort
Risolve il problema dell'ordinamento (vedi la pagina con i concetti iniziali) ed è efficiente per ordinare un piccolo numero di elementi.
La sequenza di numeri da ordinare sono anche detti chiavi.
Nel caso peggiore la sua complessità è O(n^2), nel caso migliore invece è Ω(n).
Prende come parametro un array A[1 .. n] contenente una sequenza di lunghezza n che deve essere ordinata.
I numeri di input vengono ordinati sul posto: i numeri sono risistemati allinterno dellarray A, con al più un numero costante di essi memorizzati allesterno dellarray in qualsiasi istante.
Larray di input A contiene la sequenza di output ordinata quando la procedura INSERTION-SORT è completata.
Algoritmo Merge-Sort
Questo algoritmo per l'ordinamento utilizza la tecnica Divide et impera. Infatti:
- Divide: divide la sequenza degli n elementi da ordinare in due sottosequenze di n/2 elementi ciascuna.
- Impera: ordina le due sottosequenze in modo ricorsivo utilizzando lalgoritmo
merge sort.
- Combina: fonde le due sottosequenze ordinate per generare la sequenza ordinata.
La procedura MERGE impiega un tempo Θ(n), dove n = r − p + 1 è il numero di elementi da fondere.
Nel caso peggiore impiega Θ(n log n).
Lidea consiste nel porre in fondo a ogni mazzo una carta sentinella, che contiene un valore speciale che usiamo per semplificare il nostro codice. In questo esempio usiamo ∞ come valore sentinella, in modo che quando si presenta una carta con ∞, essa non può essere la carta più piccola.
L' InsertionSort è meglio del MergeSort per array quasi ordinati sufficientemente grandi e anche per array piccoli.
HeapSort
L' HeapSort è un altro tipo di algoritmo di ordinamento che utilizza gli attributi migliori sia dell' InsertionSort sia del MergeSort.
È un algoritmo che utilizza una struttura dati detta: heap.
L' HEAP è composto da un array considerabile come un albero binario. Ogni nodo dell'albero corrisponde al valore memorizzato nella relativa cella dell'array. L'array che rappresenta l'heap è caratterizzato dalla lunghezza dell'array ovvero dal numero di elementi dell'array e dalla dimensione dell'heap ovvero dal numero di elementi dell'heap registrati nell'array (heap size [A]).
L'indice i identifica i nodi e il nodo genitore viene indicato con PARENT[i], il figlio sinistro: LEFT[i], quello destro: RIGHT[i].
Si possono avere due tipi di heap:
- max heap: il contenuto di un nodo padre è sempre maggiore o al massimo uguale al contenuto dei suoi nodi figli. In sostanza il valore maggiore si trova nella radice.
- min heap: il contenuto del nodo padre è minore o al massimo uguale al contenuto dei suoi figli.
Per l'algoritmo HeapSort si utilizza il max heap.
Si definisce altezza di un nodo il numero di archi del cammino più lungo che a partire da un nodo scende fino a un nodo foglia. Mentre l' altezza di un heap è l'altezza della sua radice.
MAX HEAPIFY
È una sottoroutine che permette di manipolare i max heap. Si suppone che l'albero su cui opera sia un max heap dove però viene violata la proprietà del max heap. In sostanza il valore in un nodo padre è più piccolo del valore del nodo figlio.
Questa sottoroutine prende a ogni passaggio il valore di ogni nodo e guarda se i suoi figli sono minori. Se lo sono la procedura termina altrimenti se i suoi figli hanno valore più grande scambia il figlio con valore maggiore con il padre. Questo accade ricorsivamente per ogni sottoalbero.
Il tempo di esecuzione è: T(n) = O(log n).
BUILT MAXHEAP
Costruzione di un max-heap a partire da un array utilizzando la procedura Max-Heapify dal basso verso l'alto.
Si inizia un ciclo for che va da [lunghezza/2] down to 1. Per esempio se la lunghezza dell'albero è 10 (10 nodi) allora parto dal 5° nodo e lo considero come radice. Chiamo Max-Heapify e guardo se il padre è più grande dei figli. Se lo è passo al successivo nodo radice (nel nostro esempio sarà il 4°) se invece non è prendo il figlio con valore massimo è lo scambio con il padre.
Tutto questo avviene fino al nodo 1 ricorsivamente per tutti i sottoalberi dell'heap.
HEAP SORT
Questo algoritmo di ordinamento inizialmente chiama la procedura BUILT MAX-HEAP per un array in dimensione [1, ... ,n].
Dopo di che si fa un ciclo for che va da n down to 2 e dato che A[1] è l'elemento maggiore lo si scambia con il minore: A[n]. A[n] viene eliminato e di conseguenza la lunghezza dell'array diventa A[1 ... n-1]. A questo punto se la nuova radice viola la proprietà del max heap chiamo la procedura MAX-HEAPIFY creando così un max heap.
La complessità di questo algoritmo è O(n log n) perchè la chiamata a BUILT - MAX-HEAP è O(n) e quella al MAX-HEAPIFY è O(log n).
CODE DI PRIORITA'
Un'applicazione degli heap sono le code di priorità. Anch'esse, analogamente agli heap, possono essere code a max-priorità e code min-priorità.
Una coda di priorità è una struttura dati che mantiene un insieme di elementi S ai quali viene associato una chiave e che vengono estratti poi dalla coda in base alla priorità più alta.
Una coda max-priorità supporta le seguenti operazioni:
- INSERT(S, x): inserisce l'elemento x in S
- MAXIMUM(S): restituisce l'elemento in S con chiave più grande
- EXTRACTMAX(S): elimina e restituisce l'elemento S con chiave più grande
- INCREASE-KEY (S, x, k): aumenta il valore della chiave di x al valore k. K dovrebbe essere almeno uguale alla chiave di x.
Una coda min-priorità supporta invece le seguenti operazioni:
- INSERT
- MINIMUM
- EXTRACT-MIN
- DECREASEKEY
Dato che gli heap possono implementare le code di priorità, occorre memorizzare un handle (aggancio) per ogni elemento dell'heap che serva a collegare l'oggetto dell'applicazione. Tipicamente questi handle sono gli indici di array ed è per questo che serve mantenerli aggiornati ogni qual volta l'oggetto dell'applicazione viene modificato.
Un heap può svolgere qualsiasi operazione con le code di priorità su un insieme di dimensione n nel tempo O(log n).
Ordinamenti in tempo lineare
Gli algoritmi di ordinamento visti finora possono essere considerati algoritmi di confronto, perché per ordinare n elementi operavano dei confronti tra gli elementi. Ora invece opereremo come se gli input fossero elementi distinti.
Alberi di decisione
Gli ordinamenti per confronti possono essere visti astrattamente come alberi di decisione che sono alberi binari completi che rappresentano i confronti effettuati da un algoritmo di ordinamento che opera su n input.
Ogni nodo interno è rappresentato da i:j per qualche 1≤i, j≤n.
Ogni nodo foglia è rappresentato da una permutazione <π(1), π(2), ..., π(n)>.
Nel ramo sinistro dell'albero ci saranno gli elementi ai ≤ aj e in quello destro gli elementi ai > aj.
Qualsiasi algoritmo di ordinamento per confronti richiede Ω(n lg n) confronti nel caso peggiore. È sufficiente determinare l'altezza dell'albero di decisione dove ogni permutazione appare come una foglia raggiungibile.
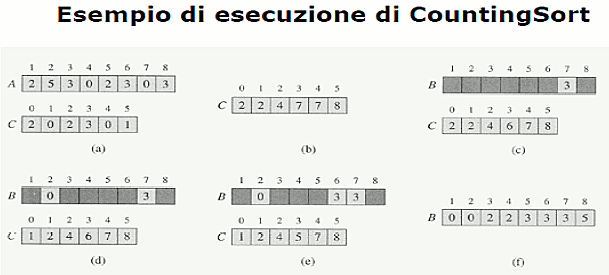
COUNTING SORT
Questo algoritmo di ordinamento suppone che ogni numero n di input sia un numero intero compreso nell'intervallo [0, k]. Per ogni elemento di input x, conta il numero di elementi minori di x, in modo tale che si possa inserire x nella sua posizione dell'array di output.
In input avremo un array A[1, n] con lunghezza n e occorrono altri due array: B[1, n] che rappresenta l'output ordinato e C[0, k] che consiste in una memoria temporanea di lavoro.
La complessità sarà Θ(n+k).
Questo algoritmo di ordinamento mantiene lordine iniziale tra gli elementi di valore uguale infatti si dice che esso è stabile.
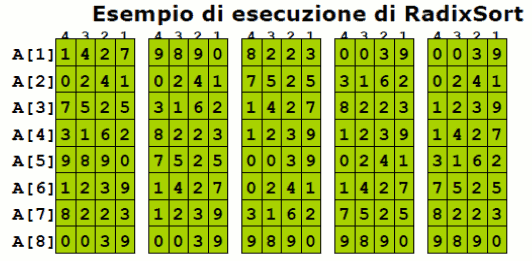
RADIX SORT
E' un algoritmo di ordinamento che serve ad ordinare un array A di n elementi in una certa base b dove ogni elemento ha d cifre. La cifra 1 è quella con ordine più basso mentre la cifra d è quella di ordine più alto. In sostanza le cifre di ogni elemento sono comprese nell'intervallo [1, k].
L'ordinamento viene effettuato eseguendo d volte un algoritmo di ordinamento stabile (CountingSort) per ordinare l'array rispetto a ciascuna delle d cifre partendo dalla mento significativa.
Complessità: T(n,d,k) = Θ(d (n + k )).
Questo algoritmo non è da preferire se lo spazio di memoria principale è limitato e quindi è meglio un algoritmo di ordinamento sul posto come quicksort.
BUCKET SORT
E' un algoritmo veloce perchè fa ipotesi sull'input (come countingsort) supponendo che esso sia generato da un processo casuale che distribuisce gli elementi uniformemente nell'intervallo [0,1). Quindi gli elementi sono numeri reali.
L'intervallo viene poi suddiviso in n sottointervalli con uguale dimensione detti bucket.
Gli n numeri di input vengono poi distribuiti nei vari bucket.
Come output l'algoritmo tornerà i bucket ordinati poi verranno esaminati elencando gli elementi in ciascuno di essi.
Il codice di questo algoritmo suppone di prendere in input un array A di n elementi dove ogni elemento A[i] deve soddisfare la seguente proprietà: 0 ≤ A[i] < 1. Inoltre, l'algoritmo, si serve di un ulteriore array ausiliario B[0...n-1] di liste concatenate (bucket) supponendo ci sia un meccanismo per mantenere tali liste.
La complessità di esecuzione è Θ(n) quindi viene eseguito in un tempo lineare.
Torna alla pagina di Algoritmi e strutture dati