Torna alla pagina di Algoritmi e strutture dati
Questa pagina è stata aggiornata GRAZIE agli appunti che AVETE INVIATO nel periodo di chiusura della sezione UniCrema!! È SERVITA A QUALCOSA, NO?! ;)
:: Algoritmi e strutture dati - Tabelle e funzioni hash ::
Hashing
Dizionario: insieme dinamico A di elementi aventi un campo key e altri campi in cui vengono memorizzate altre informazioni legate alla chiave.
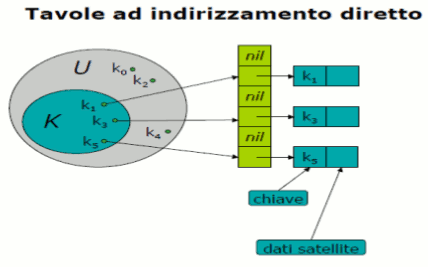
TABELLE A INDIRIZZAMENTO DIRETTO
La tecnica di indirizzamento diretto funziona bene se l'insieme universo U delle chiavi è piccolo.
Avremo una tabella T[0..m-1] dove ogni posizione o slot ha una chiave di U.
La tabella contiene i puntatori agli elementi k.
Le operazioni SEARCH, INSERT e DELETE vengono eseguite nel tempo O(1).
SVANTAGGI:
- serve riservare una memoria sufficiente per tante celle quante sono le chiavi possibili.
- Se U è troppo grande non è possibile utilizzare l'indirizzamento diretto.
- Se le chiavi effettivamente usate sono una piccola parte di U la memoria viene sprecata.
- Prima di utilizzare una tavola ad indirizzamento diretto occorre inizializzare tutti gli elementi a NIL. Tempo O(U).
TABELLE HASH
Sono array contenenti un insieme di m celle molto minore della dimensione dell'universo.
Viene utilizzata una funzione hash h per calcolare lo slot della chiave k.
L'elemento con chiave k è h(k) che può essere considerato anche come valore hash di k.
Dato che vengono utilizzati per le chiavi solo m valori e non tutto U allora lo spazio di memoria usato sarà meno rispetto alle tabelle a indirizzamento diretto.
Problema: due chiavi possono essere associate allo stesso slot e questa viene detta collisione.
Per risolvere il problema delle collisioni vengono adottati diversi approcci tra cui quello del concatenamento.
Con questa tecnica tutti gli elementi di uno slot vengono messi in una lista concatenata. L'operazione INSERT sarà eseguita in un tempo O(1) come la DELETE (T, x) per la quale non occorre prima cercare l'elemento x perchè gli viene passato subito x e non la chiave k.
Data una tabella hash T con m slot in cui sono memorizzati n elementi, si definisce fattore di carico della tabella (alfa) il rapporto n/m che indica il numero medio degli elementi memorizzati nella catena. Alfa può essere minore, uguale o maggiore di 1.
SEARCH viene eseguita nel caso peggiore nel tempo Θ(n), quindi quando tutte le chiavi sono associate allo stesso slot.
Si suppone che ogni elemento abbia la stessa probabilità di essere associato a uno qualsiasi degli m slot, indipendentemente dallo slot cui sarà associato qualsiasi altro elemento. Questa è la base dello hashing uniforme semplice (tutte le chiavi hanno probabilità 1/m).
Le operazioni vengono eseguite nel tempo O(1).
Funzioni hash
Una buona funzione hash dovrebbe soddisfare l'ipotesi dell' hashing uniforme semplice vista sopra. Però non è possibile sempre verificare questa condizione.
Un dei metodi per buone funzioni hash è il metodo della divisione che calcola il valore hash come resto della divisione tra la chiave e un determinato numero primo.
Supporremo che l'insieme universo delle chiavi sia l'insieme N dei numeri naturali.
METODO DELLA DIVISIONE
Questo metodo, che serve a creare una funzione hash, consiste nel inserire una chiave k in uno degli m slot calcolato come resto della divisione di k per m. Ovvero h(k) = (k mod m).
Questo è un metodo molto veloce perchè fa solo una operazione di divisione.
Il valore m dovrebbe preferisci diverso da una potenza di 2 (2p) quindi sarebbe meglio un numero primo non troppo vicino a una potenza esatta di 2.
METODO DELLA MOLTIPLICAZIONE
Il metodo della moltiplicazione consiste di 2 passi:
- si moltiplica la chiave k per una certa costante A, 0 < A < 1, estraendo la parte frazionaria kA;
- moltiplico la parte frazionaria per m e prendo la parte intera inferiore del risultato.
In sostanza avremo che: h(k) = m |_(kA mod 1)_|.
In questo caso m non è critico. Esso può assumere un valore 2p (potenza di 2). Però, si ha la probabilità che funzioni bene questo metodo quando, in particolare, il valore di A si avvicina al valore: (√5 -1)/2.
INDIRIZZAMENTO APERTO
Gli elementi sono memorizzati nella stessa tabella hash. Ogni slot potrà contenere un elemento dell'insieme dinamico oppure il valore NIL.
Per ricercare un elemento si scansiona ogni slot della tabella fino a quando non lo si trova.
Un difetto è che la tabella può riempirsi senza così fare altri inserimenti.
Il fattore di carico alfa non sarà mai > 1.
Il vantaggio di questa tecnica è che esclude i puntatori. Calcola la sequenza degli slot da esaminare senza seguire i puntatori.
Dato che i puntatori non ci sono posso avere più spazio per la tabella hash, a parità di memoria occupata.
Questo comporta ricerche più veloci e meno collisioni.
L'operazione INSERT scansiona la tabella fino a trovare uno slot vuoto per inserire la chiave. La sequenza di scansione dipende dalla chiave da inserire. Si chiede che per ogni chiave la sequenza di scansione sia una permutazione di < 0, 1,.., m-1> e che ogni posizione della tabella hash venga considerata come slot per una nuova chiave mentre la tabella si riempie.
La cancellazione è più complicata. Se cancello da uno slot i una chiava k non posso mettere nello slot il valore NIL perchè potrebbe essere impossibile ritrovare qualsiasi chiave k durante il cui inserimento abbiamo esaminato lo slot i ed era occupato. Una soluzione: marcare lo slot al valore speciale DELETED. Lo slot DELETED viene considerato dalla INSERT come vuoto.
Ci sono delle approssimazioni accettabili per implementare l'hashing uniforme semplice:
- scansione (o ispezione) lineare;
- scansione quadratica;
- doppio hashing.
Nella scansione lineare la funzione di hash si ottiene da una funzione hash ordinaria definita come funzione hash ausiliaria. Questo tipo di implementazione presenta un problema: clustering primario. In pratica si formano lunghe file di slot occupati e quindi il tempo per la ricerca si allunga.
Nella scansione quadratica si parte con in input una chiave, applico la funzione di hash che mi restituisce una cella e se essa è occupata rieseguo la funzione di hash con i che va da 1 a m-1. Nella tabella si fanno salti più lunghi.
È meglio di quella lineare anche se presenta anch'essa un problema anche se minore. Problema: clustering secondario: celle occupate una dopo l'altra distanziate di un certo passo. Come per la scansione lineare, anche in questa, ho solo m sequenze di scansione distinte.
Infine il doppio hashing risolve il problema dell'addensamento (clustering), utilizzando due funzioni di hash. Genera anch'esso sequenze di ispezione diverse ma molte di più rispetto alla scansione lineare e quadratica: m2. Sparpaglia maggiormente le chiavi nella tabella.
Torna alla pagina di Algoritmi e strutture dati