Torna alla pagina di Basi di Dati - Complementi
Ancora sulla concorrenza
Dopo la piacevole settimana di pausa con Sara Foresti, ecco che la titolare del corso ha ripreso la faccenda della gestione della concorrenza.
Conflict-serializzabilità
Abbiamo visto nella lezione precedente che calcolare la bontà di uno schedule secondo i dettami della view-serializzabilità è un problema np-hard, e quindi troppo costoso.
Vediamo di stringere quindi i requisiti di correttezza per trovare sistemi più rapidi dal punto di vista computazionale.
Uno di questi è proprio la conflict-serializzabilità, che è basata sul concetto di conflict-equivalenza.
Un conflict tra due operazioni si ha quando
- almeno una delle due è un'operazione di scrittura;
- avvengono sullo stesso oggetto;
- appartengono a 2 transazioni diverse.
Quindi, i casi possono essere rw, wr, ww.
2 schedule sono conflict-equivalenti quando sono definite sulle stesse transazioni, e ogni coppia di operazioni in conflitto apapre nello stesso ordine in entrambi gli schedule.
Se uno schedulo è conflic-equivalente ad uno schedule seriale, allora quel primo schedule è conflict-serializzabile.
Vediamo un esempio:
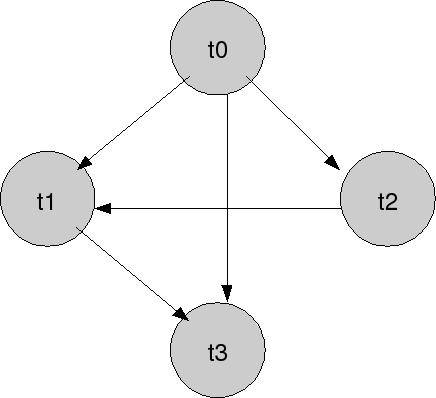
S: w0(x) r1(x) w0(z) r1(z) r2(x) r3(z) w3(z) w1(x)
I conflitti in questo schedule sono:
w0(x) r1(x) t0 -> t1
w0(x) r2(x) t0 -> t2
w0(x) w1(x) t0 -> t1
w0(z) r1(z) t0 -> t1
w0(z) r3(z) t0 -> t3
w0(z) w3(z) t0 -> t3
r1(z) w3(z) t1 -> t3
r2(x) w1(x) t0 -> t1
E adesso che faccio? Devo disegnare il grafo dei conflitti, ovvero un grafo in cui i nodi siano le transazioni, e gli archi direzionali tra i nodi siano le relazioni che ho visto qui sopra. Ad esempio, se qui sopra ho scritto
t0 -> t1
vuol dire che deve esserci un arco che va da t0 a t1.
Orbene, se questo grafo è aciclico, allora lo schedule è conflict-serializzabile. Un qualsiasi ordinamento topologico del grafo è uno schedule seriale conflict-equivalente con il mio schedule.
Che cosa è un ordinamento topologico?
Vuol dire che è una lista di nodi, fatta in modo tale che vengano rispettati gli ordini di apparizione dei nodi stessi. Se c'è un arco che va dal nodo a al nodo b, vuol dire che nella mia sequenza a deve venire prima di b, anche se in mezzo ci possono essere mille altri nodi, o nessuno. Per ogni nodo devo rispettare questa sequenza.
Ecco il mio bel grafetto:
È ciclico? No. Allora, lo schedule serializzabile tratto dal grafo è:
t0 t2 t1 t3
perché rispetta tutte le precedenze (le frecce) del grafo.
L'insieme degli schedule conflict-serializzabili (CSR) è un sottinsieme degli schedule view-serializzabili (VSR). Ciò vuol dire che un CSR è sicuramente un VSR, ma NON viceversa.
Che cosa un VSR accetta e invece il CSR rifiuta? La risposta è: le scritture cieche (blind write).
Una scrittura cieca è un'operazione di write su una risorsa, in una transzione, che in quella transazione non è preceduta da nessuna lettura della risorsa stessa. In pratica vuol dire che la transazione scrive su quella risorsa fregandosene bellamente del valore precedente.
Le scritture cieche sono tollerate da VSR, ma non da CSR, e ora facciamo un bell'esempio.
Lo schedule è:
S: r1(x) w2(x) w1(x) w3(x)
Siccome siamo bravi vediamo subito che
r1(x) legge da niente
e che w3(x) è scrittura finale di x. Inoltre ho un dato solo con 3 transazioni; se scambio l'ordine delle scritture alla fine ho sempre una scrittura che sovrascrive le altre.
Lo schedule seriale view-equivalente pertanto è:
t1 t2 t3
Adesso passiamo a vedere se è anche conflict-serializzabile.
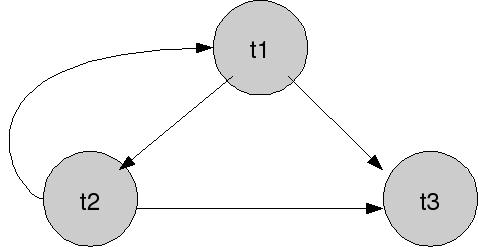
I conflitti sono:
r1(x) w2(x) t1 -> t2
r1(x) w3(x) t1 -> t3
w2(x) w1(x) t2 -> t1
w2(x) w3(x) t2 -> t3
21(x) w3(x) t1 -> t3
Il grafo è:
Si vede bene che c'è un ciclo, quindi sta roba non è conflict-serializzabile.
Decidere se un dato schedule è conflict-serializzabile ha un costo O(n) nell'ordine delle dimensioni del grafo. Molto meglio rispetto al costo polinomiale della verifica della view-serializzabilità, ma ai fini pratici è cmq troppo costoso, perché il grafo può essere bello ciccione.
E cambiare approccio?
Finora, il metodo di lavoro è stato: prendo uno schedule, vedo se è buono e se sì lo utilizzo; se no ne prendo un altro.
Di sicuro otterrò risultati buoni se non ottimi, ma il problema è che ci metterei troppo tempo!
Allora, si è pensato: invece di inventare lo schedule prima e verificarlo poi, non è più semplice seguire certe regole che automaticamente mi danno uno schedule buono?
Sì, si può, e lo si fa con i questi sistemi:
- locking a due fasi
- timestamp
- monoversione
- multiversione
Locking

An locIl lock è una variabile che mi dice come sta una risorsa.
Nella versione a 2 fasi, una risorsa può essere
- 0 = libera
- 1 = locked (bloccata)
Nella versione a 3 fasi, ho questi stati:
- 0 = libera
- 1 = lock in lettura, condivisibile
- 2 = lock in scrittura, esclusivo
Il fatto che nella versione a 3 fasi il lock in lettura è condivisibile, si spiega semplicemente: anche se 1000 persone leggono contemporaneamente una risorsa, non c'è problema, perché nessuno la modifica.
Invece, se uno vuole scriverci sopra, allora nessun altro dovrebbe leggere mentre c'è una scrittura in corso, per evitare di leggere dati inconsistenti (eg leggo un pezzo prima di una scrittura, e un pezzo dopo, e il valore risultante è balordo).
Teniamo infatti a mente che qui si parla di operazioni concorrenti.
Quando una transazione vuole il lock di una risorsa, e questo NON le viene concesso, la transazione non è che muore, semplicemente entra in lista di attesa e verrà servita, prima o poi.
Il signore che si occupa di gestire tutto ciò (la terminologia è della professoressa) si chiama gestore dei lock, e a dispetto del nome non si occupa di allocchi.
Ecco le tabelle delle transizioni tra stati:
| Lock a 2 stati
|
|
| Stato
|
| Risorsa
| unlocked
| locked
|
| lock
| OK -> locked
| NO -> locked
|
| unlock
| errore
| OK -> unlocked
|
Se sono nello stato unlocked, e mi viene richiesto un unlock per quella variabile, è ovvio che si tratta di un errore.
| Lock a 3 stati
|
|
| Stato
|
| Risorsa
| unlocked
| read locked
| write locked
|
| read lock
| OK -> read locked
| OK (c++)-> read locked
| NO -> write locked
|
| write lock
| OK -> write locked
| NO* -> read locked
| NO -> write lock
|
| unlock
| errore
| OK (c--) ->
- se c=0: unlocked
- se c>0 read locked
| OK -> unlock
|
Questa tabella è un po' più complessa.
La variabile c è un contatore, che mi conta quante sono le transazioni che stanno accedendo in lettura a quella risorsa. Ogni volta che qualcuno chiede un lock di lettura, il contatore viene incrementato. Se qualcuno fa un unlock di lettura, il contatore viene decrementato.
Se il contatore è 0, la risorsa passa nello stato unlocked. Altrimenti, rimane nello stato locked.
L'asterisco invece dice che se c'è un unico lock di lettura su una variabile, da parte di una transazione, e poi quella stessa transazione vuole un lock di scrittura, questo viene concesso. In tutti gli altri casi no. Si chiama upgrade del lock.
2PL
Nel lock a 2 fasi, dopo aver lasciato un lock, una transazione non può più acquisirne altri.
OCIO: vuol dire che non può acquisirne non solo per quella stessa risorsa, ma anche per tutte le altre risorse.
L'idea è che una transazione entri in una fase crescente, dove acquisisce tutti i lock, e poi in una fase decrescente dove li molla tutti.
Il lock a 2 fasi, 2PL per i nemici, garantisce la serializzabilità. Basta quindi seguire le regole del lock, e ho dei buoni schedule, anche se ovviamente potrei scartare dei buoni scheduli che queste regole troppo strette non ammettono, ma che sarebbero comunque view-serializzabili.
2PL è un sottinsieme di CSR.
Esisteranno quindi degli schedule che sono CSR ma non sono 2PL.
Esempio:
S: r1(x) w1(x) r2(x) w2(x) r3(y) w1(y)
Conflitti:
w1(x) r1(x) t1 -> t2
w1(x) w2(x) t1 -> t2
r1(x) w2(x) t1 -> t2
r3(y) w1(y) t3 -> t1
Non sto a disegnare il grafo, cmq ho uno schedule seriale che va bene:
t3 t1 t2
Ma sta roba non è 2PL.
Il motivo è: se t1 acquisisce il lock su x all'inizio, poi deve rilasciarlo per dare il lock a t2 sempre su x, e quindi non potrebbe riprenderlo dopo per scrivere su y.
D'altro canto, t1 potrebbe prendere all'inizio sia il lock su x che il lock su y. Ma a questo punto, avrei in mezzo la t3 che vuole un lock su y, prima che t1 possa rilasciarlo.
Quindi, non c'è verso.
OCIO: se invece NON ci fosse stata in mezzo l'operazione r3(y), tutto sarebbe filato liscio perché t1 avrebbe preso il lock di x e di y all'inizio, e avrebbe mollato il lock di x in favore di t2, ma NON avrebbe lasciato il lock di y.
2PL stretto e conservativo
All'inizio del discorso sulla gestione delle transazioni avevamo preso per ipotesi che fosse valida la commit-proiezione, cioè che tutte le trans andassero a commit e nessuna in abort.
Ma nella realtà ciò non è affatto vero, e i miei bei discorsi su lock e non lock vacillerebbero sui loro piedi.
Pertanto, si introduce il 2PL stretto, che aggiunge una norma: posso rilasciare lock solo dopo aver fatto commit o abort. Questo permette al DBMS di sapere se le mie modifiche vanno updatate al sistema oppure no.
In questo modo evito le letture sporche.
Il 2PL conservativo aggiunge invece al 2PL base la norma che prima di fare qualsiasi operazione, una trans deve avere tutti i lock che le serviranno. Evito quindi i deadlock, ovvero due trans che aspettano l'una la risorsa dell'altra e non se ne esce fuori.
Timestamp monoversione
In questo sistema, stabilisco che ogni evento deve avere un timestamp maggiore degli eventi che lo hanno preceduto.
Il timestamp può essere un contatore, oppure derivare dal clock di sistema, quello che è, purché aumenti sempre. Mi permette di avere un ordinamento totale tra tutti le trans.
Ogni oggetto (risorsa), poi, ha associate 2 informazioni aggiuntive:
- RTM(x) = il max timestamp di chi legge x
- WTM(x) = il max timestamp di chi scrive x
Vuol dire che la risorsa si porta appresso il timestamp della trans più giovane che ha avuto a che fare con lei.
Le operazioni si chiamano read(x, ts) e write(x, ts), dove x è la risorsa e ts è il timestamp della transazione che fa quella richiesta.
Ecco il comportamento adottato.
read(x, ts) va in abort se ts < WTM(x), altrimenti OK, e RTM(x) = max(RTM(x), ts).
Perché ciò? Il motivo è che se ts < WTM, vuol dire che ts è più vecchia dell'ultima trans che ha scritto su x. Se permettessi a ts di leggere, vuol dire che permetterei a ts di leggere NEL FUTURO, cioè leggere le modifiche di una trans che è venuta dopo di lei!
In caso contrario, permetto invece la lettura, e aggiorno il RTM in modo conforme alla regola.
write(x, ts) va in abort se ts < WTM(x) OR ts < RTM(x), altrimenti OK e wtm(x) = ts.
Le motivazioni sono simili.
Se ts è più vecchia dell'ultimo che ha scritto su x, allora non va bene perché non ho rispettato l'ordine temporale. Se ts è più vecchia dell'ultimo che ha letto x, parimenti non va bene perché scriverei dal passato.
In caso contario, invece, tutto OK.
Questo sistema dei timestamp quindi garantisce a priori la bontà di uno schedule in un modo eugenetico, perché semplicemente uccide tutte le transazioni che non quadrano:) Infatti il problema è che ne potrebbe far fallire un sacco, e pensiamo a quante trans sfortunate hanno un ts così sfigato che vanno sempre a male. Inoltre, siccome non so prima se una trans abortirà o no, allora devo tenere tutte le modifiche in buffer fino a che non vedo un commit o un abort definitivo.
Il vantaggio è che siccome non ci sono i lock, non c'è nemmeno il problema del deadlock.
Torna alla pagina di Basi di Dati - Complementi