Torna alla pagina di Ingegneria del Software
:: Ingegneria del Software - Appunti del 31 Marzo 2009 ::
Pattern Architetturali
Un design pattern è un modo formale per documentare la soluzione ad un problema di un certo tipo. Un tale si è accorto che i problemi che si presentavano scrivendo software erano più o meno raggruppabili in certe categorie, e quindi avevano una soluzione più o meno simile. Quindi, se uno si è trovato in un certo problema e ha redatto un pattern (una sorta di modus operandi per disegnare il sw), e io mi trovo in un problema simile, posso prendere il suo pattern e adattarlo al mio caso.
Ovviamente non è obbligatorio utilizzare pattern quando si programma, però ci facilitano di molto la vita dato che sono soluzioni riconosciute e sperimentate. Ricordiamo comunque che il pattern non è LA soluzione, ma è la forma-base del design, il che vuol dire che il codice lo devo scrivere lo stesso. In altre parole, un pattern è una soluzione parzialmente specificata. Quella totalmente specificata è il nostro software finito, mentre il pattern mi dà una base per poi lavorarci sopra.
Una particolarità del mondo dei pattern è che spesso lo stesso pattern viene presentato con nomi diversi da autori diversi.
Inoltre, se nel progetto da portare all'esame saremo in grado di identifcare un pattern, il professore ne sarà contento.
Layering
Il layering è il primo pattern della storia (?) e lo si trova praticamente ovunque. L'idea è quella di dividere il software in strati, ognuno dei quali ha precise responsabilità, e ogni strato parla solamente con lo strato sopra e quello sotto. In questo modo so esattamente a chi rivolgermi e con che semantica, e non devo tenere conto di variazioni di componenti lontani da me dei quali non dovrebbe interessarmi nulla.
Un esempio noto di layering è lo stack ISO/OSI, che ad esempio disaccoppia il DNS dal livello IP mettendoci di mezzo il protocollo TCP (o UDP). Tanto per non farci mancare un po' di sigle.
Nota di folklore: il sistema operativo DOS non adottava il layering ma ricercava un'alta intradipendenza tra componenti; UNIX invece lo persegue strettamente.
Documentare un pattern
Come si fa a documentare un pattern, cioè a "scriverlo giù" in modo che sia recuperabile, riconoscibile e riutilizzabile in futuro?
In genere si utilizzano i diagrammi di collaborazione e i diagrammi di sequenza. Vedi la lezione su UML o quella del 30 Marzo per capire un po' che cosa sono.
Model-View-Controller
Questo è il pattern più famoso, nato insieme ai primi linguaggi ad oggetti (ad esempio SmallTalk), e in diverse salse salta fuori sempre.
L'idea di fondo è che si vogliono dividere le responsabilità tra:
- interfaccia (view, cioè la GUI)
- modello (business logic)
- comunicazione tra i due (controller)
Il modello è il pezzo di sw che risolve effettivamente il mio problema, ad esempio la quadratura del cerchio.
L'interfaccia (view) è il pezzo di software che si preoccupa di mostrare al mio utente i parametri per configurare il modello, e visualizzarne l'elegante soluzione.
Il controller è il disaccoppiatore tra l'interfaccia ed il modello.
Perché mai mi serve un disaccoppiatore? Il motivo è che se cambio l'interfaccia, questo non deve riguardare in nessun modo il modello. Con un disaccoppiatore in mezzo, riesco a tenere distinte le cose (al viewer non frega niente se il modello gli passa il risultato della query sbagliato). E se ci fate caso, è una variazione sul tema del layering...
Notate che il disaccoppiatore può essere scritto anche solo con due righe di codice, non deve essere necessariamente complesso.
Il funzionamento del software sarà quindi scomposto nei seguenti momenti:
- l'utente mette nella GUI i suoi dati, e preme il pulsante "Calcola"
- la GUI passa i dati al controller
- il controller li passa al modello
- il modello fa i conti e ritorna un risultato alla GUI
Se domani decido che il mio modello è sbagliato, e ne scrivo un altro con un'altra interfaccia pubblica, la GUI posso riutilizzarla: dovrò solo aggiornare il lato del Controller che ha a che fare con il modello.
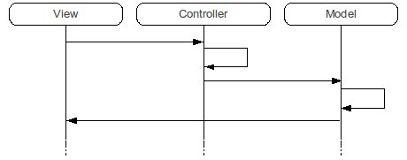
Vediamo il diagramma sequenziale:
Dal diagramma osserviamo che il disaccoppiamento funziona solo da sinistra a destra, con il controller che non fa conoscere i dettagli del modello alla view, ma non il viceversa: M deve restituire alla V quello che lei si aspetta o che comunque sarà in grado di gestire.
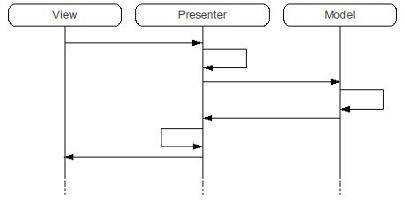
Model-View-Presenter
L'idea dell'MVC è buona, ma il disaccoppiamento può essere reso ancora più efficace facendo in modo che lavori in full duplex: la GUI comunica solo con il Controller, e idem per il modello. In questo modo Modello e GUI rimangono ben distanti, così come deve essere.
A questo punto però il Controller non si chiama più controller, bensì Presenter, ma la differenza è solo quella citata sopra. Anzi, il MVP è una variante talmente popolare di quella originale che spesso viene chiamata MVC al posto dell'altra.
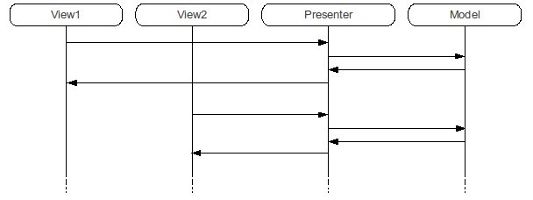
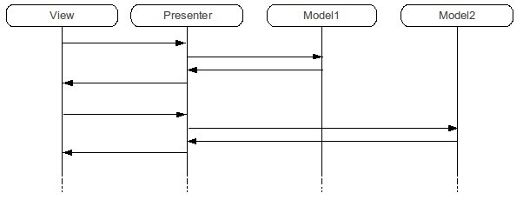
Vediamo due esempi illuminanti sull'utilità di questo pattern.
Primo esempio: gestire la navigazione web da telefono e da PC. Abbiamo due interfacce, una per il telefono e una per il computer, ma il modello sotto rimane sempre lo stesso: il presenter non solo disaccoppia, ma smista al modello giusto.
Secondo esempio: abbiamo un software che gestisce funzioni matematiche, e che può avere moduli diversi a seconda del ramo in cui è specializzato (aritmetica, algebra, ...). A seconda di quello che vuole l'utente, il presenter smisterà la richiesta al modello responsabile.
Notiamo per inciso che questa è la dimostrazione che il computer e l'uomo sono molto, molto diversi. La necessità di disaccoppiamento nello scrivere software decente ha la stessa importanza della necessità di accoppiamento che caratterizza l'essere umano. Noi e le macchine non andremo mai d'accordo.
Observer-Notifier
Consideriamo ora un altro pattern, che non sia solo orientato alle funzioni ma anche alle performance, ovvero che ottimizzi le risorse e prenda le decisioni (parallelizzare le attività, concentrarle o distribuirle su più componenti, ...) più adatte a limitare gli sprechi e aumentare le prestazioni. Ha diversi nomi:
- Observer-Notifier (quello più usato)
- Observer-Observed
- Listener
Quale che sia il nome, il problema cui si pone come soluzione è quello in cui alcuni componenti siano costretti ad attendere il risultato di componenti più lenti.
Ci sono due soluzioni semplici, che ovviamente non vanno bene:
- l'Osservatore si connette all'Osservato e attende finché non arrivano notizie
- L'Osservatore si connette a intervalli regolari all'Osservato e chiede se ci sono notizie
Perché non vanno bene? Nel caso 1 il problema è che se non succede niente, io rimango tutto il giorno ad aspettare. Nel caso 2 è che potenzialmente posso passare il giorno a fare polling (estrarre campionamenti ogni tot tempo) sull'Osservato, senza ottenere comunque nulla, oppure perdermi dei passaggi intermedi se faccio polling con una frequenza troppo bassa. Inoltre, in entrambi i casi potrei perdere tempo ad attendere un evento che non mi interessa nulla, solo per non dovermi perdere l'evento successivo che invece mi interessa molto.
Soluzione: si crea un servizio intermedio, detto notifier, che fa da servizio di allerta.
Il Notifier si connette all'Osservato, e si fa dire tutto sempre. Poi, l'Osservatore a sua volta si registra presso il Notificatore, e gli dice di quali e quanti eventi dell'Osservato desidera essere messo a conoscenza. Quando il Notificatore rileva eventi nell'Osservato, guarda la sua lista di Osservatori e decide a quali di essi inviare l'esempio.
Caricare tutto sul Notifier non è come spostare il problema dall'Observer su di lui, perché avrà sì lo stesso carico di lavoro, ma distribuito su più clienti. Se infatti non è giustificato che l'osservatore sia impegnato full time in attesa di un evento, la cosa ha senso per un processo come il notifier.
Anche questa è una variazione sul tema del layering.
Da Casi d'Uso a Diagramma delle Classi
Dai CdU siamo già in grado (più o meno) di tirare fuori il diagramma di collaborazione e il diagramma di sequenza. Adesso è giunto il momento di tirare fuori da questi il diagramma delle classi.
Prendiamo l'ultimo pattern che abbiamo visto, quello del Notifier. Avrò sicuramente tre classi:
- Observer
- Notifier
- Observed
Nel diagramma di sequenza avrò delle frecce che rappresentano le chiamate. Ebbene: ogni freccia verso una classe rappresenta un metodo pubblico di quella classe.
C'è anche un'altra cosa da notare. Supponiamo che la classe Observer voglia modificare qualche attributo della classe Notifier, ad esempio "Frequenza Di Polling". In un ipotetico linguaggio di programmazione, basterebbe scrivere in un metodo qualsiasi di Observer:
Notifier myNotifier;
myNotifier.PollingFrequency = 10
Questo modo di modificare i parametri altrui non è molto bello, per questi motivi:
- non c'è modo di tracciarlo in nessun diagramma UML
- avviene all'insaputa del legittimo possessore dell'attributo PollingFrequency
Per quanto riguarda il punto 2, se Notifier è stato scritto presupponendo che PollingFrequency non superasse mai il valore 10, il poter modificare questo attributo alla carlona dall'esterno è veramente pericoloso.
Il punto 1 invece mi dice che nella mia progettazione non ho alcuno modo di scrivere, e quindi tener conto, dell'eventualità della modifica del valore di PollingFrequency da parte di qualcuno. Non lo posso diagrammare, quindi lo lascio alla libera iniziativa del programmatore etc. etc.
Pertanto, tutti gli attributi di una classe che possono essere modificati dall'esterno NON devono essere accessibili direttamente al pubblico, ma devono essere modificati tramite dei metodi scritti apposta, i cosiddetti check e set.
Ad esempio, la classe Notifier potrebbe avere dei metodi così:
public int checkPollingFrequency() {
return this.PollingFrequency;
}
public bool setPollingFrequency(int newValue) {
if (newValue > 0) && (newValue <= 10) {
this.PollingFrequency = newValue;
return true;
} else {
return false;:
}
}
Quindi, se qualcuno dall'esterno vuole modificare il valore di PollingFrequency, da un lato non potrà farlo impunemente, e dall'altro, dovendo ricorrere ad un metodo, il suo tentativo sarà ben segnalato nel diagramma delle sequenze.
Torna alla pagina di Ingegneria del Software