Torna alla pagina di Informatica Teorica
:: Informatica Teorica - Linguaggi non regolari ::
Appunti & Dimostrazioni del 17 Marzo
Esempio 1 - linguaggio non regolare
Supponiamo di dover realizzare un automa a stati finiti n.d. che riconosca il seguente linguaggio:
B = {0n1n | n>=0}
Il compito dell'automa sembra semplice, capire se la stringa in ingresso ha lo stesso numero di 0 e di 1. Il problema è che il numero n di occorrenze è limitato solo inferiormente, ma non superiormente. Ci ritroviamo per cui nelle condizioni di dover affrontare un numero illimitato di possibilità con un numero finito di stati.
Dal momento che non riusciamo a definire un automa a stati finiti che lo riconosca, possiamo affermare che il linguaggio B è non regolare.
Ocio però: non possiamo basarci solo sulla quantità di memoria (quindi di stati) richiesta per distinguere tra linguaggi regolari e non. Ci sono infatti molti casi che apparentemente prevedono un numero illimitato di possibilità, ma in realtà sono regolari. Ad esempio il linguaggio:
D = {w | w ha un ugual numero di occorrenze di 01 e 10 come sottostringhe}
Sembra analogo al linguaggio B, ma in realtà è regolare. Fidatevi!
Come facciamo allora a distinguere tra linguaggi regolari e non regolari? Ovvio, con le solite affascinanti prove matematiche!
Pumping lemma
Pumping lemma non è solo il nome del mio criceto, ma anche quello del teorema che permette di provare la (non) regolarità dei linguaggi.
Se A è un linguaggio regolare, allora esiste un numero p (chiamato pumping length) tale che se s è una qualunque stringa in A di lunghezza almeno p, allora s può essere divisa in tre parti, s=xyz, che soddisfino le seguenti tre condizioni:
- per ogni i>=0, xyiz ∈ A
- |y|>0
- |xy|<=p
Spiegazione
Il teorema del pumping lemma dice che tutti i linguaggi regolari godono di una certa proprietà, che se verificata in un linguaggio L ne certifica la regolarità. La proprietà è questa: qualunque stringa di L deve poter essere divisa in tre parti, chiamate x y e z, tali che la stringa xynz (ottenuta replicando, o restando in tema, pompando n volte l'elemento centrale) appartenga ancora ad L. In altre parole, ogni stringa di L deve contenere una sottostringa che possa essere ripetuta un qualunque numero di volte.
Dimostrazione
Sia M=(Q,Σ,δ,q1,F) un DFA che riconosca il linguaggio A, e sia p il numero di stati di M.
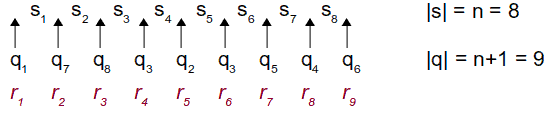
Sia s=s1s2..sn una stringa in A di lunghezza n, dove n>=p.
Sia infine r1, ... , rn+1 la sequenza di stati che M assume durante la computazione di s, tale che ri+1=δ(ri,si) per 1<=i<=n. Adesso seguitemi bene:
- se la lunghezza della stringa è n, allora il numero di stati che M attraversa è n+1;
- il numero di stati di M è p, e come abbiamo già detto n>=p;
- ma se n>=p, allora sicuramente n+1>p, quindi la sequenza di stati deve avere una ripetizione!
Probabilmente si capisce meglio con un esempio:
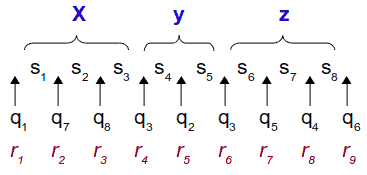
Premettendo che gli indici degli stati nell'esempio sono del tutto casuali, possiamo affermare che in questo caso: q1 è lo stato iniziale, q3 è lo stato che si ripete, q6 è quello finale su cui M accetta.
Se chiamiamo il primo degli stati che si ripetono rj e il secondo rl, possiamo suddividere la stringa in ingresso in questo modo:
- x = s1...sj-1
- y = sj...sl-1
- z = sl...sn
Riprendendo l'esempio avremo:
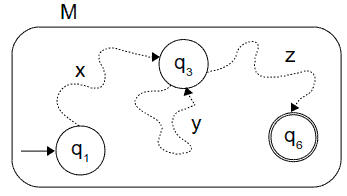
Dato che la sottostringa x tiene occupato M dallo stato r1 ad rj, la sottostringa y lo tiene occupato da rj ad rj, e la sottostringa z da rj ad rn+1, che è lo stato accettante, allora M deve accettare xyiz per qualsiasi i>=0 (prima condizione del teorema). Se dovessimo infatti rappresentare il tutto con uno pseudo-automa (in cui le frecce curve tratteggiate permettono di ignorare gli stati intermedi) avremo qualcosa del genere:
Ovvero, non ci interessa quante volte si ripete il ciclo su q3, tanto poi comunque ci sposteremo (attraversando z) verso lo stato finale.
Verifichiamo invece la seconda condizione del teorema osservando che poiché j≠l, allora per forza di cose |y|>0, perché nel peggiore dei casi (tra gli stati che si ripetono non ce ne sono altri) |y| è pari a 1.
Infine, dato che tra i primi p+1 elementi della sequenza di stati deve esserci almeno una ripetizione, ovvero l<=p+1, allora |xy|<=p (terza condizione del teorema).
Ecco dunque dimostrato il teorema del pumping lemma per il riconoscimento dei linguaggi regolari.
Pumping Lemma su Esempio 1
Ora che siamo freschi di teoria, usiamo la strategia del pumping lemma per dimostrare che il linguaggio B dell'Esempio 1 è non regolare. La dimostrazione si fa per contraddizione, ovvero si assume che B sia regolare e poi si dimostra che ciò porta a contraddizioni.
Il linguaggio B diceva: B = {0n1n | n>=0}
Assumiamo che B sia regolare e diciamo che p è il pumping length.
Definiamo s una stringa del tipo 0p1p. Dato che s è in B e che la sua lunghezza è maggiore di p, il teorema del pumping lemma ci garantisce che s può essere diviso in tre parti s=xyz, dove per ogni i>=0 la stringa xyiz è ancora in B.
Consideriamo tre possibili casi:
- la sottostringa y è composta di soli 0. Ma allora ad esempio la stringa xyyz avrebbe uno 0 in più rispetti agli 1, quindi non sarebbe più in B, violando la prima condizione del pumping lemma;
- la sottostringa y è composta di soli 1. Stesso discorso, ma con gli 1 che superano il numero di 0 violando le condizioni del teorema;
- la sottostringa y è formata di 0 e di 1. In questo caso un'eventuale stringa xyyz avrebbe sì lo stesso numero di 0 e di 1, ma non rispetterebbe più il formato secondo cui tutti gli 0 precedono gli 1. Nada, anche in questo caso la nuova stringa non è più in B.
Tutti e tre i casi ci portano a una contraddizione, quindi B non è regolare.
Torna alla pagina di Informatica Teorica