Torna alla pagina di Sistemi Operativi
:: Appunti 2.0 ::
Deadlock
Introduzione
In sistemi multiprogrammati è comune che processi e thread diversi competano per l'accesso ad un numero limitato di risorse, ognuna delle quali può mettere a disposizione un certo numero di istanze identiche che soddisferanno le richieste allo stesso modo. Da questa situazione possono scaturire problemi di uso scorretto e inconsistente delle risorse, cui si fa fronte con politiche di sincronizzazione. Quindi, perché un processo possa utilizzare una risorsa dovrà effettuare le seguenti operazioni in sequenza:
- richiesta, che se non può essere soddisfatta immediatamente impone che il richiedente attenda il suo turno
- uso
- rilascio, passo essenziale, in cui il processo libera la risorsa
Questa soluzione non è priva di problemi, dal momento che può portare a due tipi di situazioni deleterie: lo starvation e il deadlock. Del primo si è già parlato abbondantemente nel capitolo sulla schedulazione, ora invece tratteremo del secondo caso.
Deadlock
Un gruppo di processi si dice in uno stato di deadlock (o stallo) quando ogni processo del gruppo sta aspettando un evento che può essere generato soltanto da un altro processo del gruppo. Gli eventi in questione possono essere di vario tipo, nel nostro caso l'acquisizione e il rilascio delle risorse, che queste siano fisiche (componenti e periferiche) o logiche (ad esempio, file, semafori, ecc). Nella condizione di deadlock i processi non terminano mai la loro esecuzione e le risorse di sistema a loro assegnate rimangono bloccate, impedendone l'accesso agli altri processi.
Formalmente, ho una condizione di deadlock se e solo se si verificano simultaneamente quattro condizioni:
- mutua esclusione (mutual exclusion), ovvero almeno una risorsa deve essere usata in un modo non condivisibile: se due processi chiedono l'accesso a una risorsa, uno dei due deve essere messo in attesa. E' intuibile che se non avessi risorse per cui competere allora non ci sarebbe nemmeno deadlock
- possesso e attesa (hold & wait), in cui un processo che possiede già almeno una risorsa, per terminare la computazione deve attendere che se ne liberino altre occupate
- nessun rilascio anticipato (no pre-emption), perché se lo consentissi non si potrebbe mai bloccare l'accesso a una risorsa dato che chi la utilizza verrebbe forzatamente terminato
- attesa circolare (circular wait). Se ad esempio ho tre processi P1, P2 e P3, ho una situazione di attesa circolare se P1 attende il rilascio di una risorsa occupata da P2, anche lui in attesa di una risorsa associata a P3, il quale aspetta il rilascio di quella allocata a P1. Notare come questa condizione implichi anche il possesso e attesa
Grafo di allocazione delle risorse
Per verificare con precisione la sussistenza di un deadlock si utilizza il grafo di allocazione delle risorse, ovvero un grafo costituito da un insieme di nodi che rappresentano sia i processi Pi che le risorse Ri del sistema, e di archi che si suddividono in archi di richiesta (che vanno da P ad R) e archi di assegnazione (da R a P). Se ho quindi un arco uscente da una risorsa ed entrante in un nodo, significa che quella risorsa è assegnata a quel nodo; se ho invece un arco uscente da un nodo ed entrante in una risorsa significa che quel nodo ha fatto richiesta di quella risorsa.
Per convenzione, i nodi Pi sono rappresentati graficamente con dei cerchi e le risorse Ri con dei rettangoli, all'interno dei quali possono esserci più puntini che rappresentano le istanze (nessun puntino -> un'unica istanza). Peculiarità degli archi è che mentre quelli di richiesta non devono indicare un'istanza in particolare, quelli di assegnazione sì. Data questa definizione, si può dimostrare che se il grafo non contiene cicli allora nessun processo del sistema è in deadlock; se invece contiene un ciclo allora ci può essere una situazione di stallo. Bisogna infatti verificare che tra le risorse coinvolte nel ciclo ci sia almeno un'istanza in più disponibile, altrimenti ho il deadlock.
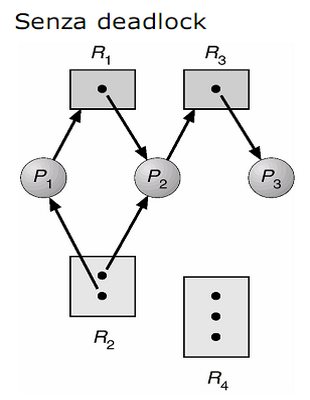
Di seguito tre esempi:
Abbiamo tre processi (P1, P2, P3) e quattro risorse (R1, R2, R3, R4). R1 ed R3 hanno un'unica istanza, mentre R2 ne ha due ed R4 tre.
In particolare:
Il processo P1 ha richiesto R1 che però è già stato assegnato a P2, quindi rimane in attesa.
La risorsa R2 mette a disposizione due istanze, che pur essendo identiche possono essere usate in parallelo. Non ho conflitti dato che il principio di mutua esclusione si applica solo sulla stessa istanza.
Il processo P3 spezza la possibilità di formare un'attesa circolare, non avendo richieste pendenti su altre risorse già occupate. Una volta che ha terminato l'utilizzo di R3, lo rilascia sbloccando P2 (e per propagazione anche P1).
Non ho quindi deadlock.
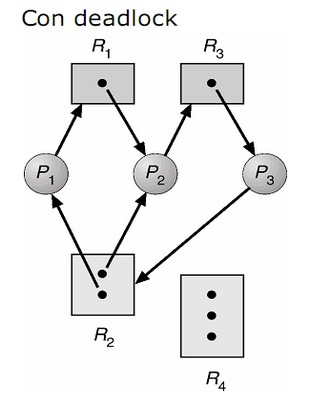
Come prima abbiamo tre processi (P1, P2, P3) e quattro risorse (R1, R2, R3, R4). R1 ed R3 hanno un'unica istanza, mentre R2 ne ha due ed R4 tre.
In particolare:
Il processo P1 ha richiesto R1 che però è già stato assegnato a P2, quindi rimane in attesa.
La risorsa R2 mette a disposizione due istanze, che pur essendo identiche possono essere usate in parallelo. Non ho conflitti dato che il principio di mutua esclusione si applica solo sulla stessa istanza.
Il processo P3 richiedendo la risorsa R2 che non ha istanze disponibili, si mette in attesa
Si sono creati così due cicli:
P1 -> R1 -> P2 -> R3 -> P3 -> R2 -> P1
P2 -> R3 -> P3 -> R2 -> P2
I processi P1, P2 e P3 sono in deadlock. Il processo P2 sta infatti aspettando la risorsa R3 che è tenuta dal processo P3, il quale sta aspettando che P1 o P2 rilascino un'istanza di R2. In più il processo P1 sta aspettando che P2 liberi R1. I processi potrebbero rimanere in questo stato di attesa indefinitamente.
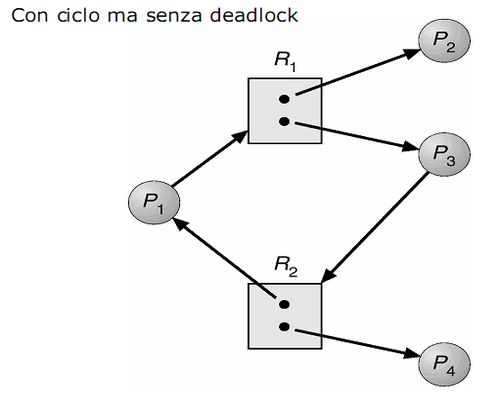
Abbiamo quattro processi (P1, P2, P3, P4) e due risorse (R1, R2) ognuna delle quali con due istanze.
In particolare:
Esiste un ciclo tra P1 -> R1 -> P3 -> R2 -> P1.
Ho due processi P2 e P4 che non sono coinvolti nel ciclo.
Questa situazione dimostra che se le risorse hanno più istanze, posso avere dei casi in cui ho cicli ma non deadlock. In questo caso, P2 e P4 prima o poi termineranno la loro computazione e rilasceranno un'istanza, che potrà essere utilizzata da P1 e P3 per superare lo stallo.
Metodi di gestione del deadlock
Esistono diversi metodi di gestione degli stalli, ognuno dei quali coporta un diverso carico di lavoro sul processore. Bisogna dunque scegliere quello che si rivela il miglior compromesso tra "uso di risorse di calcolo" e "criticità della presenza del deadlock" nel sistema.
Le principali strategie di gestione sono le seguenti:
- ignorare del tutto il problema e fingere che i deadlock non si presentino mai nel sistema. Posso permettermi di adottare tale metodo quando l'eventualità che accadano stalli sia rarissima, ad esempio legata ad un errore hardware o software che avviene con frequenza molto bassa. Questa politica normalmente consente all'utente che non vede progredire il suo processo di abortirlo o riavviare tutto il sistema. In questo modo, essendo di per sé raro il fenomeno di stallo, sarà difficile che si ripresentino nello stesso ordine le richieste alle risorse che avevano condotto al deadlock precedente. Può sembrare strano, ma questa soluzione è quella usata dalla maggior parte dei sistemi operativi, Unix e Windows compresi. Perfino la Java Virtual Machine non gestisce deadlock, viene lasciato tutto al programmatore
- prevenzione del deadlock (deadlock prevention), che garantisce a priori, nel momento in cui vengono fatte le richieste, che queste non generino situazioni di stallo. Consiste in un insieme di metodi atti ad accertarsi che almeno una delle condizione necessarie viste prima non possano verificarsi
- evitare il deadlock (deadlock avoidance), che non impedisce ai processi di effettuare le richieste, ma se queste potrebbero causare stalli le blocca. Richiede che i processi forniscano al sistema operativo delle informazioni supplementari su quali e quante risorse chiederà nell'evoluzione della sua computazione
- rilevazione e recupero del deadlock (deadlock detection & recovery), che non applica nessuna tecnica per impedire l'occorrere di una situazione di stallo, ma fornisce degli algoritmi per la sua rilevazione ed eliminazione
E se nessuna di queste strategie ha successo? Il sistema si arenerebbe nello stato di deadlock, con un conseguente progressivo deterioramento delle prestazioni dovuto al blocco indefinito delle risorse che impediscono l'evoluzione dei processi. Spesso in questi casi l'unica soluzione è il riavvio manuale del sistema operativo.
Vediamo ora più in dettaglio le varie strategie di gestione.
Prevenzione del deadlock
Prevenire il deadlock significa fare in modo che almeno una delle quattro condizioni per cui si verifica sia soddisfatta. Studiamo i casi separatamente.
Bisogna anzitutto verificare che il principio di mutua esclusione sia applicato solo su quelle risorse intrinsecamente non condivisibili, come ad esempio una stampante; estenderlo anche a risorse condivisibili aumenta solo il rischio di insorgere in situazioni di stallo. Un esempio di risorse intrinsecamente condivisibili sono i file in sola lettura, cui l'accesso simultaneo può tranquillamente essere garantito a tutti i processi che ne avessero bisogno.
Per evitare invece la condizione di possesso e attesa si deve fare in modo che ogni volta che un processo chiede risorse non ne possegga già qualcun'altra. A tale scopo si possono usare due tecniche:
- un processo chiede e ottiene tutte le risorse prima di iniziare l'esecuzione. Se ad esempio un processo deve modificare mille file e infine stamparli, accederà a tutte le risorse all'avvio (stampante compresa) e ne manterrà il possesso per tutta la durata della computazione e solo quando termina le rilascerà. Se il sistema operativo non riesce a dargli tutti gli accessi, il processo non viene nemmeno attivato. Lo svantaggio di questa soluzione non è da poco. Può infatti passare molto (troppo) tempo prima che il processo usi tutte le risorse da lui bloccate all'apertura, manentendo inutilmente altri processi in attesa rallentando di conseguenza il parallelismo del sistema
- un processo che possiede alcune risorse e vuole chiederne altre deve prima rilasciare tutte quelle che già detiene, quindi richiedere l'accesso a quelle che gli servono più quelle che aveva già. Una volta ottenute, il processo esegue le computazioni opportune e quindi le rilascia a disposizione di altri. Pur guadagnando in parallelismo rispetto alla soluzione precedente, il limite di tale tecnica è che bisogna strutturare opportunamente il programma tenendo conto che una risorsa (e il suo contenuto) terminato l'uso possa essere modificata da altri processi, e questo per un programmatore non è un compito banale
In entrambi i casi ho un basso utilizzo delle risorse, che possono essere assegnate ma rimanere inutillizzate per un periodo lungo; talmente lungo che potrebbe avvenire una starvation.
Se non applicare la pre-emption soddisfa una delle quattro condizioni di deadlock, imporla ove possibile scongiura gli stalli. Quando è possibile? Quando il rilascio anticipato non crea problemi di consistenza delle informazioni.
Come nel caso precedente, possiamo utilizzare due tecniche:
- se un processo detiene delle risorse e ne chiede altre per le quali deve attendere, allora deve rilasciare anticipatamente tutte le risorse possedute, che vengono aggiunte in una lista di tutte quelle per cui il processo sta aspettando. Il processo sarà fatto ripartire solo quando potrà ottenere tutte le risorse, vecchie e nuove. Siamo sostanzialmente nello stesso approccio dell' hold & wait, con la differenza che qui non devo attendere il termine d'uso della risorsa da parte del processo dato che gli viene imposto
- se un processo chiede risorse si verifica prima di tutto che siano disponibili, nel qual caso gli viene dato l'accesso. Altrimenti se sono già associate a un altro processo che però non le usa perché sta attendendo altre risorse, viene imposto a quest'ultimo di rilasciarle anticipatamente e vengono aggiunte alla lista delle risorse per cui il processo richiedente è in attesa. Se invece le risorse sono già associate a un altro processo che le sta usando, deve attendere che questi le rilasci. Riassumendo, si applica la pre-emption solo su processi in attesa di altre risorse, altrimenti no.
Va considerato che questi protocolli non possono essere applicati indistintamente su tutti i tipi di risorse, ad esempio sarebbero impensabili su stampanti o unità nastro.
Quarta e ultima condizione da scongiurare per prevenire il deadlock è l' attesa circolare. La tecnica per prevenirlo è forse la più contorta vista finora, e richiede che sia dato un ordinamento globale univoco su tutti i tipi di risorsa Ri, in modo che sia sempre possibile sapere se una è maggiore o minore di un'altra rispetto all'indice i'. Tale indice è un numero naturale che dovrebbe essere assegnato con un certo criterio, rispettando i comuni ordini d'uso delle risorse; ad esempio è plausibile che un file sia utilizzato prima di una stampante, dunque ha senso che il suo indice sia inferiore a quello della periferica.
L'ordinamento di per sé non previene il deadlock, bisogna applicare la seguente politica, divisa in due punti:
- se un processo chiede un certo numero di istanze della risorsa Rj e detiene solo risorse Ri con i<j, se le istanze sono disponibili gli vengono assegnate, altrimenti dovrà attendere;
- se invece richiede istanze della risorsa Rj e detiene risorse Ri con i>j, allora il processo dovrà prima rilasciare tutte le sue risorse Ri, quindi richiederle tutte, vecchie e nuove comprese.
Ad esempio se il processo P detiene la risorsa R25, potrà chiedere solo risorse indicizzate da R26 in su, e non da R25 in giù, a meno che non rilasci tutte quelle che ha già. Questa tecnica impedisce che più processi possano attendersi l'un l'altro: gli indici lo impediscono.
Normalmente applicare questi protocolli di controllo è responsabilità degli sviluppatori di applicazioni, ma esistono alcuni software che svolgono il lavoro per loro. Questi programmi sono noti come Witness.
Evitare il deadlock
La deadlock prevention applica alcune regole su come devono essere fatte le richieste di accesso alle risorse, garantendo che almeno una delle quattro condizioni perché si abbiano stalli non sia verificata. Il problema è che sono regole molto restrittive, che determinano un basso rendimento del sistema e di utilizzo delle periferiche. Una possibile alternativa è verificare a priori se la sequenza di richieste e rilasci di risorsi effettuate da un processo porta a stalli, tenendo conto delle sequenze dei processi già accettati nel sistema. Ciò significa evitare il deadlock, e richiede che i processi forniscano al sistema operativo alcune informazioni sul loro comportamento futuro, così che questo possa sapere in qualsiasi momento:
- il numero massimo di risorse per ogni processo
- quante risorse sono assegnate e quante sono disponibili
- la sequenza delle richieste e dei rilasci da parte di un processo
Una volta ottenute queste informazioni, il che non è sempre semplice, bisognerà implementare un algoritmo che ne tenga conto e metta in moto una serie di procedure perché il sistema non entri mai in uno stato di deadlock. Introduciamo a tal proposito il concetto di stato sicuro.
Uno stato si dice sicuro se il sistema operativo può allocare le risorse richieste da ogni processo in un certo ordine, garantendo che non si verifichi deadlock. Attenzione però, essere in uno stato non sicuro non significa essere certi di arrivare in una situazione di stallo in futuro, ma non poter assicurare il contrario; tanto basta perché sia considerato non sicuro. Più formalmente, uno stato è sicuro soltanto se esiste una sequenza sicura, ovvero una sequenza di processi P1, P2, ... , Pn tale che le richieste che ogni processo Pi può fare possono essere soddisfatte dalle risorse attualmente disponibili più tutte le risorse detenute dai processi Pj, con j<i. In altre parole, è una sequenza di processi tale che le richieste di ognuno possono essere soddisfatte con le risorse già disponibili o in via di rilascio dai processi precedenti ad ogni singolo processo i-esimo. Si tratta quindi di un ordine con cui andare a considerare le richieste dei processi, garantendo così di non avere attese circolari.
Facciamo un esempio. Se ho un processo Pi che ha bisogno di alcune risorse che non sono immediatamente disponibili, dovrà attendere che tutti i Pj che vengono prima di lui abbiano rilasciato le proprie. Quando ciò accade, Pi può ottenere finalmente tutte le risorse necessarie, completare la sua esecuzione e infine rilasciarle. Una volta terminato Pi, il processo Pi+1 potrà ottenere le sue risorse e così via. Se si soddisfa tale sequenza, lo stato del sistema è sicuro.
Compito degli algoritmi che si occupano di evitare situazioni di stallo è continuare ad accertarsi che il sistema, all'avvio nativamente in stato sicuro, permanga in tale stato ad ogni richiesta di allocazione delle risorse. Dato che ciò può comportare una maggiore tempo di attesa per i processi, lo sfruttamento delle risorse potrebbe essere più basso del suo potenziale.
Studiamo ora due possibile tecniche per implementarlo.
Variante del grafo di allocazione delle risorse
Se abbiamo un sistema di allocazione delle risorse con un'unica istanza per risorsa, per individuare i deadlock si può utilizzare una versione modificata del grafo di allocazione delle risorse, in cui oltre agli archi di richiesta e assegnazione c'è anche l' arco di prenotazione. Rappresentato come una freccia tratteggiata, indica quali risorse saranno prima o poi necessarie ad un processo perché possa portare avanti la propria computazione; quest'informazione deve essere data prima che inizi l'esecuzione. Rilevare un ciclo sugli archi di prenotazione significa che un processo in futuro potrebbe fare una richiesta che porta il sistema in una situazione di stallo, il che va evitato.
Esempio:
Nel grafo di allocazione delle di risorse di sinistra notiamo come sia P1 che P2 prenotino entrambi la risorsa R2, che mette un'unica istanza a disposizione. Se, come vediamo nel grafo di destra, R2 concede l'accesso a P2 cadiamo in uno stato non sicuro, dal momento che basta che P1 faccia anche lui richiesta ad R2 perché si chiuda il ciclo e si abbia una situazione di stallo. La richiesta di P2 deve dunque essere rifiutata dal sistema.
Algoritmo del banchiere
Il limite del grafo di allocazione delle risorse è che non può essere usato se ho risorse con istanze multiple, perché l'esistenza di un ciclo non implica necessariamente un deadlock. L' algoritmo del banchiere permette invece di gestire tali situazioni, pur essendo in media meno efficiente data la sua maggiore complessità computazionale. L'idea che sta dietro l'algoritmo è che il sistema operativo prima di concedere delle risorse a un processo, gli chiede il numero massimo di istanze di cui avrà bisogno; se verifica che l'allocazione lo lascia in uno stato sicuro, allora la concede, altrimenti il processo dovrà attendere finché il sistema non ritenga di avere abbastanza risorse per farlo progredire. Bisogna dunque che siano soddisfatte due ipotesi iniziali:
- ogni processo deve dichiarare a priori il numero massimo di istanze di cui avrà bisogno, o il sistema gli rifiuta la richiesta. Proprio come un banchiere, che deve sapere quanti soldi dare a un cliente
- ogni processo dovrà resistuire in un tempo finito le risorse utilizzate. Poi della durata del processo in sé all'algoritmo del banchiere non importa nulla, l'importante è che prima o poi rilasci le risorse. Che ci metta molto o ci metta poco, nemmeno questo importa: l'unica cosa che si vuole è evitare il deadlock, a qualunque prezzo.
Una delle maggiori complessità dell'algoritmo del banchiere è che deve gestire parecchie strutture dati. Dati m numero delle risorse ed n numero dei processi, avrò:
- available[1..m], le risorse disponibili. Ogni i-esima posizione indica il numero di istanze di tipo i disponibili
- max[1..n, 1..m], una matrice che definisce il numero massimo di risorse che un processo può chiedere. Se
max[i][j] è uguale a k, allora il processo Pi può chiedere al più k istanze di risorse del tipo Rj
- allocation[1..n, 1..m], una matrice che dice il numero di risorse di ogni tipo attualmente assegnate a ogni processo. Se
allocation[i][j] è uguale a k, allora il processo Pi detiene attualmente k istanze di risorse del tipo Rj
- need[1..n, 1..m]', una matrice che specifica il numero di risorse che il processo dovrà ancora richiedere nella sua vita. In particolare,
need[i][j] = max[i][j] - allocation[i][j]
Queste strutture possono variare nel tempo sia in dimensione che in valore.
L'algoritmo di distingue in due parti, una che verifica la sicurezza ed uno per la richiesta delle risorse.
L'algoritmo di sicurezza consiste nella verifica dello stato sicuro, deve cioè trovare - se esiste - una sequenza sicura. Di seguito lo pseudocodice, coi commenti sotto ogni passo:
Work[1..m]
\\ un vettore che rappresenta quali sono le richieste di risorse
Finish[1..n]
\\ un vettore che rappresenta quali processi hanno completato la computazione, e quindi hanno rilasciato a un certo punto le risorse
- Work = Available; Finish[i] = false per i = 0, 1, ... , n-1
\\ fase di inizializzazione: segno come disponibili gli elementi del vettore delle risorse, e assegno valore negativo per ogni processo del vettore Finish (dato che non hanno ancora terminato la computazione)
- Si cerca i tale che
- Finish[i]==false
- Needi <= Work
Se non esiste tale i, vai al passo 4
\\scandisco Finish finché trovo un processo non ancora terminato e che richiede un numero di risorse inferiore a quelle indicate nel vettore Work
- Work = Work + Allocation[i]; Finish[i] = true
Vai al passo 2
\\ rappresenta il caso in cui posso soddisfare la richiesta. Una volta che il processo ha terminato la computazione e rilasciato le risorse, andrò ad aggiornare il vettore delle allocazioni disponibili, sommandogli le risorse che erano state assegnate al processo i-simo (ormai rilasciate)
- Se, per ogni i, Finish[i]==true, allora lo stato è sicuro
\\ notare che l'algoritmo può richiedere m x n2 operazioni prima di arrivare a questo passo
Fatta questa verifica, l'algoritmo prosegue con la gestione delle richieste. Come prima, lo pseudocodice è commentato sotto i vari passi.
Request[i]
\\ rappresenta la richiesta del processo Pi in un certo momento
- Se Request[i]<=Need[i], vai al passo 2
Altrimenti solleva errore: il processo ha ecceduto il numero massimo di richieste
\\ se il numero di richieste è minore (o al più uguale) al numero massimo di richieste che saranno effettuate da i, allora vai al passo 2. Se lo supera, allora il processo aveva cannato a fornire al sistema il numero massimo di richieste che avrebbe chiesto
- Se Request[i]<=Available, vai al passo 3
Altrimenti Pi deve attendere: risorse non disponibili
\\ se il numero di richieste è minore o uguale a quelle disponibili in quel momento, allora posso passare al passo 3, in cui tali richieste saranno soddisfatte.
- Si ipotizzi di stanziare le risorse richieste
- 3.1 Available = Available - Request[i]
- 3.2 Allocation[i] = Allocation[i] + Request[i]
- 3.3 Need[i] = Need[i] - Request[i]
Se lo stato risultante è sicuro, al processo Pi vengono confermate le risorse assegnate. Altrimenti Pi deve aspettare per le richieste Request[i] e viene ristabilito il vecchio stato di allocazione delle risorse.
\\la sicurezza dell'assegnamento viene valutata in tre punti: in 3.1 viene diminuito il numero di risorse disponibili in base alle richieste del processo; in 3.2 viene incrementanto il numero di risorse assegnate al processo; in 3.3 viene decrementato il numero di risorse del processo che ancora devono essere soddisfatte. Se queste allocazioni mi lasciano in uno stato sicuro (e lo verifico con l'algoritmo di verifica visto prima) confermo tutto, altrimenti non posso dare le risorse al processo perché entrerei in uno stato non sicuro. In questo secondo caso riporto tutto alla situazione precedente all'allocazione e lascio che il processo attenda.
Rilevazione e ripristino del deadlock
Senza algoritmi per prevenzione o evitare il deadlock, tale situazione può verificarsi. Sistemi di questo tipo devono mettere a dispozione algoritmi per rilevarne la presenza dopo che sono avvenuti, e per ripristinare una situazione di corretto funzionamento eliminando lo stallo. Vedremo come questi requisiti possano adattarsi a sistemi con istanze singole o multiple delle risorse.
Rilevazione
Abbiamo già imparato che nel caso in cui tutte le risorse abbiano un'unica istanza, il grafo di allocazione delle risorse ci torna sempre molto utile. Utilizzeremo in questo caso una variante ridotta, il grafo di attesa (o wait for), dal quale sono stati rimossi tutti i nodi che rappresentavano le risorse e gli archi si trovano ora a collegare due processi. La loro nuova interpretazione è che un certo processo Pi richiederà una risorsa posseduta da un altro processo Pj, quale risorsa non ci interessa. Ad esempio nel grafo di attesa seguente il processo P1 vuole accedere a qualche risorsa detenuta da P2.
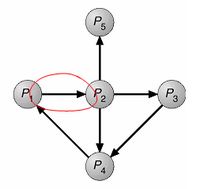
Il sistema dovrà dunque mantenere aggiornato il grafo di attesa dei suoi processi ed eseguire periodicamente l'algoritmo di rilevazione di eventuali cicli, che segnalano l'occorrenza di un deadlock. Cosa si intende per periodicamente? Si può decidere di farlo partire ogni volta che un processo chiede una risorsa e scopre che è occupata, ma data la frequenza dell'evento avrei un overhead troppo elevato. Un'altra soluzione potrebbe essere far partire l'algoritmo ad intervalli di tempo prefissati; è vero che tra un intervallo e l'altro potrebbero essersi verificati degli stalli, ma è sicuramente meno costoso che eseguirlo ad ogni richiesta fallita.
Se invece nel sistema sono presenti risorse con istanze multiple, bisogna cambiare il tipo di algoritmo di rilevamento, molto simile a quello del banchiere.
Work[1..m]
Finish[1..n]
- Work = Available; per i = 0, 1, ... , n-1
se Allocation[i] != 0, allora Finish[i] = false;
altrimenti Finish[i] = true;
- Si cerca i tale che
- Finish[i] == false
- Requesti <= Work
Se non esiste tale i, vai al passo 4
- Work = Work + Allocation[i]; Finish[i] = true
Vai al passo 2
- Se Finish[i] == false per qualche i, con 0 = i < n, allora si ha deadlock
Inoltre, se Finish[i] == false, allora il processo Pi è in deadlock
Vanno fatte anche in questo caso le considerazioni sulla frequenza di esecuzione dell'algoritmo di rilevamento viste prima per i grafi d'attesa.
Ripristino
Quando un algoritmo di rilevazione riscontra effettivamente una situazione di stallo, può comportarsi in due modi: informa l'utente della situazione e lascia a lui il compito di gestirla manualmente, oppure fa in modo che sia il sistema operativo ad occuparsi del ripristino automatico. Quest'ultimo può adottare come soluzione la terminazione forzata di un processo o il rilascio anticipato delle risorse, che andremo a vedere maggiormente in dettaglio.
Esistono due strategie per ripristinare il sistema dal deadlock terminando i processi coinvolti, entrambe che comportano il rilascio delle risorse assegnate ai processi abortiti. Esse sono
- abortire tutti i processi in deadlock, che interromperà sì il deadlock, ma a caro prezzo dato che vengono persi tutti i risultati parziali che i processi terminati avevano calcolato fino a quel punto. R' funzionale, ma comporta uno spreco consistente di risorse computazionali
- abortire un processo alla volta fino a eliminare il ciclo di deadlock, che causa per contro un overhead considerevole, dal momento che ad ogni processo abortito sarà da eseguire l'algoritmo di rilevazione del deadlock (per capire quando fermarsi). A ogni modo, esistono diversi criteri su cui basarsi per scegliere l'ordine di eliminazione dei processi. Ad esempio potrei considerare le loro priorità, da quanto tempo sono in esecuzione o quanto tempo gli manca perché terminino, quante e quali tipi di risorse stanno usando o devono ancora richiedere, quanti processi devono essere terminati o ancora se il processo è interattivo o no.
Se invece si volesse eliminare il deadlock usando il rilascio anticipato delle risorse, bisognerebbe deallocare forzatamente certe risorse a determinati processi, passandone poi l'accesso ad altri, e continuare a farlo fino a quando viene superata la situazione di stallo. Perché ciò avvenga senza problemi, si devono tener conto di tre aspetti fondamentali:
- scelta della vittima, ovvero quali risorse e quali processi devono essere interrotti. Anche in questo caso vengono considerati diversi criteri per la selezione, molto simili a quelli visti per la terminazione
- rollback. Se si forza un processo a rilasciare le risorse che sta usando, ovviamente non lo si mette più nelle condizioni di continuare la sua normale esecuzione. Bisognerebbe quindi riportarlo (rollback) ad un certo stato sicuro e farlo ricominciare da lì. Ciò implica che il sistema operativo debba tener traccia di più informazioni sui processi, e questo non accade molto spesso. Per questo motivo molto spesso il rollback è totale, ovvero abortisce il processo e lo fa ripartire dall'inizio
- starvation. Dato che la selezione della vittima è basata soprattuto su fattori costo, può succedere che in caso di deadlock sia sempre lo stesso processo ad essere abortito. Non potendo progredire si arena in una situazione di starvation, risolvibile considerando nel fattore costo anche il numero di rollback imposti.
Torna alla pagina di Sistemi Operativi