Torna alla pagina di Sistemi Operativi
:: Appunti 2.0 ::
L'interfaccia del file system
Il file system fornisce il supporto per la memorizzazione e l'accesso ai dati e ai programmi, ed è l'aspetto più visibile agli utenti del sistema operativo.
E' composto dai file (che contengono dati o programmi), dalla struttura della directory (che li organizza e ne fornisce le informazioni) e in alcuni sistemi dalle partizioni (che separano logicamente o fisicamente grandi insiemi di directory).
Il concetto di file
Il concetto di file è qualcosa di estremamente generale, cerchiamo di darne alcune definizioni. In primo luogo esso rappresenta un insieme di informazioni, è identificato in modo univoco da un nome ed è memorizzato in un dispositivo di memoria secondaria così che sia sempre disponibile anche in seguito a un riavvio del sistema. Può essere anche considerato come una sequenza di bit (o di byte, o di righe, o di record) il cui significato è definito dal creatore del file e dall'utente.
In un file possono essere memorizzati molti tipi diversi di informazioni: programmi sorgente o eseguibili, testi, immagini, ... Ognuno di essi ha una specifica struttura strettamente legata al tipo, così che possa essere trattato opportunamente dal sistema operativo.
Attributi del file
Gli attributi del file possono variare col sistema operativo, ma in genere sono:
- nome, ovvero il nome simbolico del file composto generalmente da una stringa di caratteri. Viene mantenuto in forma leggibile dagli utenti ed è indipendente dal processo, dall'utente e dal sistema operativo che lo hanno creato
- identificatore, un'etichetta solitamente numerica che identifica in modo univoco il file all'interno del file system
- tipo
- locazione, il puntatore al dispositivo e alla locazione fisica del file
- dimensione corrente, espressa in byte, parole o blocchi
- protezione, ovvero informazioni per il controllo dell'accesso
- tempo, data e identificativo dell'utente, tutte informazioni utili per la sicurezza e il controllo
I valori degli attributi dei file vengono mantenuti nel descrittore del file contenuto nella directory, anch'essa residente in un'unità di memoria secondaria.
Operazioni sui file
Per poter meglio definire un file è opportuno descrivere il tipo di operazioni che lo riguardano:
- creazione, che consta di due passaggi: ricerca dello spazio nel file system e creazione di un descrittore nella directory in cui registrare il nome, la locazione ed altre informazioni
- scrittura, che avviene attraverso una chiamata di sistema in cui si specifica sia il nome del file che le informazioni da scriverci dentro. Dato il nome, il sistema operativo cerca nella directory la posizione fisica del file, quindi mantiene un puntatore di scrittura alla locazione in cui avverrà la scrittura successiva
- lettura, che avviene per mezzo di una chiamata di sistema in cui si indica il nome e dove dovrebbe essere allocato in memoria il record successivo. Sia per la lettura che per la scrittura viene mantenuto un puntatore alla posizione corrente del file per risparmiare spazio e ridurre la complessita delle operazioni
- riposizionamento all'interno di un file, in cui si setta il puntatore alla posizione corrente con un determinato valore. E' anche detto ricerca nel file e non implica un accesso alle informazioni
- cancellazione, che dopo aver cercato nella directory il file col nome indicato prevede il rilascio di tutto lo spazio a lui assegnato (disponibile ora per gli altri) e l'eliminazione del suo descrittore
- troncamento, che cancella il contenuto del file ma non i suoi attributi (salvo naturalmente la dimensione, che viene azzerata)
A queste sei operazioni di base possono esserne aggiunte altre (come l' accodamento o la rinomina) e possono essere combinate tra loro (ad esempio la copia o lo spostamento).
Dato che la maggior parte di queste operazioni prevede la ricerca nelle directory del descrittore del file (operazione lenta se effettuata su memorie secondarie), molti sistemi operativi prevedono l'apertura di un file con la chiamata di sistema open(). Questa operazione ne comprende molte altre, ovvero:
- la verifica delle autorizzazioni all'accesso
- l'identificazione del descrittore del file nel file system
- l'identificazione della locazione nei dispositivi fisici
- la verifica e gestione dello stato di uso condiviso
- l'inizializzazione delle informazioni per una gestione efficiente
Viene inoltre mantenuta una tabella dei file aperti che contiene tutte le informazioni sui file attualmente utilizzati, e dalla quale vengono tolti solo in seguito a una chiamata di sistema close() o nel momento in cui i processi che li hanno aperti terminano.
In sistemi più complessi multiutente come UNIX si preferisce usare due tabelle, una per il processo e una per il sistema, così da permettere a due processi diversi di accedere allo stesso file. A tal fine vengono mantenute nelle tabelle le seguenti informazioni:
- puntatore al file, che indica l'ultima posizione di lettura o scrittura ed è unico per ogni processo operante sul file
- contatore delle aperture di un file. Solo quando il suo valore arriva a 0 il sistema operativo può rimuovere il descrittore del file dalla tabella dei file aperti
- posizione del file su disco
- diritti d'accesso, che specificano le modalità d'accesso al file e sono riportate nella tabella dei file aperti relativa al processo
Infine, alcuni sistemi operativi permettono di bloccare un file aperto (o parti di esso) per impedire ad altri processi di accedervi. Ne esistono di tre tipi: blocco esaustivo o condiviso (in lettura, su richiesta), blocco esclusivo (in scrittura, su richiesta) e blocco consigliato (in scrittura, obbligatorio, imposto).
Tipi di file
Una tecnica comune per indicare il tipo di file è includerlo nel nome sottoforma di estensione, ovvero un codice (generalmente di tre caratteri) che lo identifica. Le estensioni non sono richieste, quindi se un'applicazione apre un file che non ne ha cercherà di aprirlo nel formato che si aspetta.
Struttura del file
Abbiamo detto che dal tipo del file dipende anche la sua struttura interna. Il sistema operativo deve supportare ognuna di queste strutture, quindi deve avere un codice di gestione specifico per ognuna di esse, il che può diventare molto ingombrante.
UNIX ha un numero minimo di strutture di file supportate e considera ogni file come una sequenza di byte (di 8 bit) che il sistema operativo non interpreta in alcun modo. Se questo da un lato garantisce la flessibilità, dall'altro dà poco supporto demandando alle applicazioni il compito di includere il proprio codice interpretativo.
In generale un sistema operativo non deve avere troppi tipi supportati o sarebbe troppo voluminoso, ma non deve averne nemmeno troppo pochi o renderebbe la programmazione difficoltosa.
Struttura interna del file
Esistono tre tipi di strutturazione di un file:
- nessuna, ovvero una sequenza di byte o parole una dietro l'altra
- struttura semplice, suddivisa per linee a lunghezza fissa o variabile
- struttura complessa, tipica dei documenti formattati o dei file caricabili rilocabili
Metodi di accesso
Accesso sequenziale
L' accesso sequenziale è il metodo più semplice, in cui le informazioni nel file vengono elaborate in ordine un record dopo l'altro. E' l'accesso tipico degli editor e dei compilatori.
Accesso diretto
L' accesso diretto o relativo è basato su un modello di file composti da record logici di lunghezza fissa che permettono ai programmi di leggere e scrivere velocemente senza un ordine particolare. Sono molto utili per l'accesso immediato a grandi quantità di informazioni, per questo motivo le basi di dati li adottano frequentemente.
Le operazioni sui file devono essere modificate per includere come parametro il numero del blocco fisico relativo, che rappresenta un indice riguardante l'inizio del file e che fa in modo che l'utente non possa accedere a blocchi che non fanno parte del file stesso.
Alcuni sistemi operativi supportano sia l'accesso diretto che quello sequenziale, altri solo uno dei due. E' possibile inoltre simulare il sequenziale a partire dal diretto, ma con risultati poco soddisfacenti.
Altri metodi di accesso
Un possibile metodo di accesso basato su quello diretto è l' accesso indicizzato che prevede la costruzione di un indice, ovvero una serie ordinata di puntatori a vari blocchi fisici. Per trovare un record logico nel file bisogna prima cercarlo nell'indice, quindi usare il puntatore per accedere direttamente al file e al record voluto. Questa struttura permette di eseguire una ricerca in un file di grosse dimensioni con poche chiamate di I/O.
Se l'indice diventa troppo grande è a sua volta indicizzabile; si avrà dunque un indice primario che punterà a quello secondario che referenzia i dati effettivi.
Struttura della directory
I file system possono essere molto vasti dunque è prioritario organizzarli al meglio. Anzitutto ogni disco è diviso in una o più partizioni (o volumi), cioè delle strutture a basso livello in cui sono memorizzati file e cartelle. Notare che un sistema può avere più partizioni o averne una in comune con altri sistemi. Esse consentono all'utente di preoccuparsi esclusivamente della directory logica e dei file, trascurando tutti i problemi di allocazione che ci sono dietro. Ogni partizione mantiene le informazioni sui file in essa contenuti nella directory del dispositivo (o indice del volume).
La directory è una struttura informativa che può essere vista come una tabella simbolica il cui compito è tradurre i nomi dei file nei corrispondenti descrittori. E' in grado di supportare il raggruppamento di file in base a criteri logici, la gestione efficiente dell'accesso ad essi, la loro condivisione e protezione.
Le operazioni che si possono compiere sulle directory sono:
- ricerca di un file
- creazione e cancellazione
- elenco di una directory
- rinomina, che può far cambiare la posizione dei file nella struttura generale
- attraversamento del file system, che permette di accedere a ogni directory e ad ogni file all'interno della struttura
Per strutturazione del file system si intende l'organizzazione globale dei file del sistema nelle varie directory. Vediamone alcuni tipi.
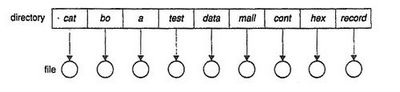
Directory a singolo livello
La directory a singolo livello è la struttura più semplice, in cui tutti i file si trovano in un'unica directory.
Ha un grosso limite: dato che i nomi dei file in una stessa cartella devono essere univoci, quando il loro numero aumenta (soprattutto se si pensasse di rendere tale sistema multiutente) la loro gestione e raggiungibilità diventerebbe decisamente ostica. Inoltre non essendo permesso alcun raggruppamento risulta impossibile dare una qualsiasi struttura logica a file legati a diverse attività.
Questa strutturazione era pensata per sitemi monoutente con una piccola memoria di massa, in cui non esisteva ancora il concetto di omogeneizzazione tra risorse fisiche e informative.
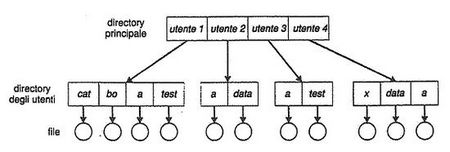
Directory a due livelli
Nella struttura della directory a due livelli ogni utente ha una propria home directory (UFD) che contiene solo e soltanto i suoi file. Quando ha inizio un processo dell'utente o un utente si connette, viene effettuata una ricerca nella directory principale (MFD) indicizzata per nome utente o numero dell'account, in cui ogni descrittore punta al rispettivo UFD. In questo modo utenti diversi possono avere file con lo stesso nome dato che ognuno opera esclusivamente sui file nella propria home directory.
Tale struttura viene mantenuta aggiornata da un programma di sistema che si preoccupa di creare o cancellare le UFD e i rispettivi descrittori nelle MFD. Può essere anche vista come un albero a due livelli, dove la directory principale è la radice, le home sono i figli e i file sono le foglie. Con questa rappresentazione è possibile definire un percorso univoco per ciascun file lungo l'albero.
Il limite delle directory a due livelli è che risolvendo il problema del conflitto dei nomi isolando un utente dall'altro non ha tenuto conto dell'eventualità che in alcuni casi gli utenti vogliano cooperare e accedere a file condivisi.
Per quanto riguarda la condivisione esiste però un'eccezione, ovvero una speciale directory utente che contiene tutti i file di sistema configurata in modo che se un utente non trova un file nella propria UFD potrà provare a cercarlo lì.
Visione logica del file system
Come avere una vera astrazione dell'informazione? Come organizzarla in modo logico prescindendo da dettagli come proprietà, condivisioni, ... ? Il modo più naturale per trovare informazioni è raggrupparle per aspetti comuni in sottoinsiemi disgiunti via via più specifici. Si può intuitivamente rappresentare questa struttura con un albero, dal quale è facilmente deducibile che nessun file potrà appartenere a direttori diversi dato che può avere un unico percorso radice-file.
Con questa struttura non sappiamo più dove si trovano fisicamente i file nel disco, ma lo sappiamo a livello logico ed è tutto di guadagnato. La posizione logica è il percorso del file, ovvero la sequenza di cartelle a partire dalla radice che attraverso per arrivare al file stesso.
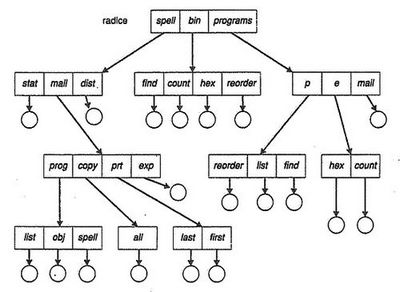
Directory strutturata ad albero
La directory strutturata ad albero estende di fatto la struttura della directory a un albero di altezza arbitraria. Gli utenti possono così creare delle proprie sottodirectory e organizzare in esse i file, applicando una visione logica al file system. L'albero ha una directory radice (root) e ogni file ha un percorso assoluto (che inizia dalla radice e attraversa tutte le sottodirectory fino al file specificato) e uno relativo (che parte dalla directory corrente).
La cartella corrente è quella attualmente richiesta dall'utente e dovrebbe essere quella che contiene i file di attuale interesse; proprio per questo motivo si può cambiare in qualsiasi momento.
Questo sistema consente all'utente di realizzare una struttura arbitraria dell'insieme dei file, e gli permette di accedere oltre che ai propri anche a quelli altrui.
Un'interessante decisione politica in una struttura ad albero riguarda la cancellazione di una directory: si possono eliminare cartelle non vuote oppure sì? Da un punto di vista implementativo entrambi i meccanismi sono piuttosto facili da realizzare, e in particolare il secondo è più conveniente ma più pericoloso.
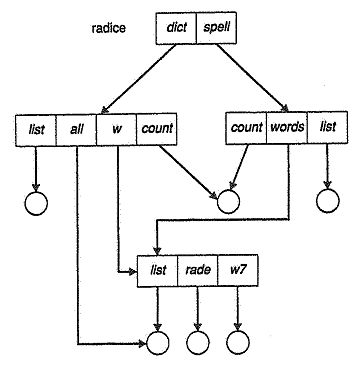
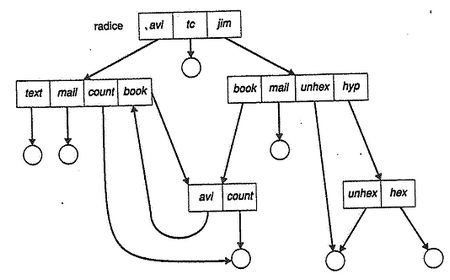
Directory a grafo aciclico
La struttura a grafo aciclico è un'estensione della struttura ad albero e consente a due o più utenti di condividere uno stesso file o una stessa cartella facendola apparire in due diverse sottodirectory. Notare due cose: 1. non si tratta di copie, gli interventi avvengono sullo stesso elemento 2. non ci sono cicli, come immaginabile.
Come si implementa? O utilizzando i link (quindi puntatori ad altri file o cartelle) o duplicando le informazioni contenute nei loro descrittori (uno per directory). In quest'ultimo caso abbiamo però alcuni fattori critici:
- bisogna sempre garantire la coerenza delle copie in seguito a scritture
- un file può avere diversi percorsi assoluti
- bisogna fare attenzione al momento della cancellazione di file condivisi perché potrei rimanere con puntatori pendenti. Una soluzione potrebbe essere non cancellare un file finché non sono stati cancellati tutti i riferimenti ad esso, il che implica il mantenimento di una lista o di un contatore
Directory a grafo generale
La struttura a grafo generale è la generalizzazione (appunto) di quella precedente e permette l'esistenza di cicli al suo interno. Se in questo modo viene risparmiato il dispendioso onere di assicurare che non ci siano cicli, dall'altro si perdono la semplicità degli algoritmi di attraversamento del grafo e la possibilità di determinare quando non ci sono più riferimenti ad un file. Se infatti un file si autoreferenziasse, anche se non venisse mai più usato non si potrebbe mai cancellarlo dato che il suo contatore sarebbe diverso da 0.
Il sistema adottato per individuare i file e le cartelle da cancellare è chiamato garbage collection e consiste nel raggiungimento e marcatura di tutti gli elementi del file system in cui si riesce ad arrivare. Tutto ciò che non è stato marcato viene inserito in una lista dello spazio libero e dunque considerato disponibile. Questo sistema è tuttavia estremamente dispendioso sui dischi e per questo motivo viene usato raramente.
Montaggio del file system
Il montaggio di un file system è quell'operazione che lo rende disponibile ai processi del sistema. La procedura è diretta: al sistema operativo viene fornito il nome del dispositivo e il punto di montaggio, ovvero la locazione in cui il file system da montare si aggancerà a quello esistente. A questo punto viene verificato che il dispositivo abbia un file system valido (del formato previsto) e quindi annota nella propria struttura della directory che tutto è andato a buon fine.
Questa procedura è configurabile, ad esempio è possibile specificare se il punto di montaggio deve essere una cartella vuota oppure no, se il file system agganciato può vedere quello esistente oppure no, se un file system può essere montato in diversi punti oppure no, ecc.
Condivisione dei file
Il caso di più utenti
Per implementare la condivisione e la protezione in sistemi operativi che supportano la multiutenza si deve conservare per ogni file o cartella più attributi di quanti ne sarebbero necessari in un sistema monoutente.
La strategia più diffusa introduce il concetto di proprietario e di gruppo. Il primo è l'utente che può modificare gli attributi e garantire l'accesso, il secondo invece definisce un sottoinsieme di utenti che possono voler condividere l'accesso al file. Nella maggior parte dei sistemi operativi l'attributo del proprietario si realizza con l'identificatore di utente (ID) e quello di gruppo con l'ID di gruppo. Notare che ogni utente può appartenere a più gruppi.
File system remoti
Con l'evoluzione della tecnologia delle reti è oggi possibile avere numerose strade per la condivisione dei file: trasferimento manuale tra macchine mediante programmi come ftp, utilizzo di file system distribuiti (DFS), world wide web, ecc.
Il modello Client-Server
I file system remoti permettono a un computer di montare uno o più file system da una o più macchine remote. La macchina che contiene i file è il server, che li specifica a livello di partizione o sottodirectory. La macchina che chiede accesso a tali file è il client, che può essere identificato con un nome di rete o un indirizzo IP. La comunicazione client-server deve essere quanto più controllata e sicura possibile data la sensibilità dell'operazione.
Una volta montato il file system remoto i client effettuano le richieste d'accesso ai file condivisi attraverso il protocollo DFS. Il server controlla se su quella determinata macchina l'utente con quell'ID che ha richiesto un accesso è autorizzato; se sì gli viene ritornato un descrittore (file handle) e l'applicazione può compiere l'operazione desiderata.
Sistemi informativi distribuiti
I sistemi informativi distribuiti forniscono un accesso unificato alle informazioni necessarie per il calcolo remoto. Ad esempio il server dei nomi del dominio (DNS) effettua la traduzione del nome dell'host in un indirizzo di rete valido per tutta Internet. Altri sistemi informativi distribuiti utilizzano una combinazione di username/password/user ID/group ID per identificare i file ed effettuare operazioni in ambiente distribuito.
Per quanto riguarda i meccanismi di assegnazione dei nomi si sta consolidando il protocollo leggero di accesso alle directory (LDAP), che garantisce con un'autenticazione singola sicura l'accesso a tutti i computer del sistema e alle informazioni in essi contenuti.
Modalità di guasto
Nei file system remoti le possibilità di guasto sono molto maggiori rispetto a quelli locali a causa della maggiore complessità dell'architettura, che si estende lungo una rete. Oltre ai guasti locali si sommano dunque gli altri legati alla comunicazione tra host, danni che rendono impraticabili gli accessi ai file system remoti.
Va detto però che i rischi ci sono, ma non così alti. E' tuttavia preferibile in caso di guasto evitare di terminare tutte le operazioni in atto e di attendere qualche tempo confidando che il malfunzionamento venga riparato o bypassato.
Semantica della coerenza
La semantica della coerenza si applica a quelle operazioni in cui più utenti accedono contemporaneamente a un file condiviso e ne specifica le modalità d'accesso per garantire la consistenza delle informazioni. In altre parole definisce le modalità di aggiornamento dei file condivisi: modifiche immediatamente visibili, modifiche visibili solo dopo la chiusura dei file, visibili solo nelle sessioni successive alla chiusura del file, file condivisi immutabili, ...
Per garantirla è necessario introdurre il concetto di sessione, ovvero quella serie di accessi (in lettura o scrittura) che si effettuano sul file tra una open() e una close(), quindi per tutta la sua durata di apertura.
Protezione
Quando le informazioni sono memorizzate in un computer si desidera mantenerle al sicuro dai danni fisici (affidabilità) e da accessi impropri (protezione).
Tipi di accesso
La risposta più adeguata alla necessità di proteggere i file è l' accesso controllato, che tende a limitare i tipi di accesso accordando o meno permessi per operazioni di lettura, scrittura, esecuzione, accodamento, cancellazione o elenco. Esistono altre tipologie di accesso che possono essere controllate (ad esempio la rinomina) ma sono a livello più alto.
Controllo dell'accesso
Il sistema più conveniente per controllare e proteggere gli accessi è considerarli dipendenti dall'identità degli utenti. Si può dunque associare ad ogni file una lista di controllo degli accessi (ACL) che il sistema operativo consulta per verificare che l'utente è autorizzato o meno all'accesso richiesto. La versione più usata della ACL è quella ridotta, in cui sono definiti tre soli tipi di utente: proprietario (chi ha creato il file), gruppo (utenti che condividono il file e hanno tipi di accessi simili), universo (tutti gli altri). In questo modo sono necessari solo tre campi per definire la protezione, in UNIX di 3 bit ciascuno: rwx-rwx-rwx.
Altri metodi di protezione
Un altro sistema di protezione potrebbe essere associare ad ogni file una password, ma poi si richiederebbe all'utente di ricordarsene troppe e sicuramente userà sempre la stessa vanificando l'utilità della tecnica. Sarebbe meglio applicare una password solo alle directory, ma basterebbe scoprirne una per accedere a molte risorse informative.
Torna alla pagina di Sistemi Operativi