Torna alla pagina di Sistemi Operativi
:: Appunti 2.0 ::
Processi
Il multi-tasking
I primi computer permettevano di eseguire un solo programma alla volta, cedendo a esso il controllo completo del sistema. Ciò comportava uno scarso sfruttamento del processore a causa dei tempi morti per l'attesa del completamento delle operazioni di I/O. Della multiprogrammazione, ovvero avere più programmi caricati contemporaneamente in memoria, non venivano dunque sfruttate le intrinseche potenzialità computazionali.
Il passo successivo non poteva che essere quello di utilizzare questi tempi morti di attesa per eseguire più programmi, almeno apparentemente, in parallelo. Il multi-tasking garantisce proprio questo, gestendo la turnazione dei programmi sul processore quando il programma in esecuzione è in attesa della risposta delle periferiche. La multiprogrammazione rimane ovviamente una condizione necessaria, e in particolare sarebbe preferibile avere tra tutti i programmi caricati in memoria almeno uno che dia qualcosa da fare al processore, o il multi-tasking non sarebbe sfruttato. Chiaro che ciò non può avvenire sempre, l'importante è che accada il più spesso possibile.
I processi
I programmi in esecuzione di cui abbiamo appena parlato sono i processi, l'unità di lavoro nei moderni sistemi a condivisione di tempo (time-sharing). Sono composti dal codice del programma (anche detto sezione di codice) e dai dati del programma, che a loro volta si suddividono in:
- variabili globali, allocate in memoria centrale nell'area dati globali
- variabili locali e non locali delle procedure del programma, memorizzate in uno stack
- variabili temporanee introdotte dal compilatore, tra cui ricordiamo il program counter, caricate nei registri del processore
- variabili allocate dinamicamente durante l'esecuzione, memorizzate in uno heap
Importantissimo sottolineare che i programmi non sono processi. I primi sono infatti entità passive, una sequenza di istruzioni contenute in un file sorgente salvato su disco. I processi sono invece entità attive, con un program counter che specifica l'istruzione successiva da eseguire, un gruppo di istruzioni in uso e una particolare istanza dei dati su cui era stato mandato in esecuzione il programma. E' per questo che posso benissimo avere due processi associati allo stesso programma, verranno comunque considerati come istanze di esecuzione distinte dello stesso codice. Ad esempio, posso aprire due finestre di Firefox e gestirle separatamente: il loro sorgente è uguale, la sezione dati è differente.
Un altro modo di pensare i processi è come flussi di esecuzione della computazione. Indipendentemente da cosa fanno o rappresentano, possiamo intuitivamente sostenere che se due flussi sono separati, anche i processi lo sono, e che in questo caso potrebbero evolversi coordinandosi (processi sincronizzati) o in modo assolutamente autonomo (processi indipendenti).
In base ai flussi posso inoltre distinguere due modelli di computazione, il processo monolitico e quello cooperativo. Nel primo vengono eseguite tutte le istruzioni del programma in un'unico flusso dall'inizio alla fine; mentre nel secondo vengono generati una serie di processi concorrenti che lavorano (a livello logico) in parallelo per conseguire lo stesso scopo. Da notare come i processi monolitici siano tra loro indipendenti, mentre i vari processi che computano a livello cooperativo interagiscono tra loro (ad esempio condividendo i risultati, sincronizzandosi, ecc). La realizzazione di tale modelli di computazione può dunque essere di tre tipi: programma monolitico eseguito come tale, programma monolitico che genera processi cooperanti, programmi separati eseguiti come cooperanti.
Evoluzione della computazione
Lo stato di evoluzione della computazione può essere considerata una terza componente dei processi, ed indica a che punto è arrivata la loro esecuzione. Tali stati fotografano istante per istante le istruzioni eseguite e il valore dei dati del processo, permettendoci di prevedere come evolverà il programma semplicemente conoscendo l'istruzione successiva indirizzata.
Si parla di evoluzione perché durante l'esecuzione del processo avviene una trasformazione delle informazioni. Lo si può dunque immaginare come una funzione, in cui su valori iniziali vengono eseguite delle operazioni che produrranno un risultato finale, o come una macchina a stati finiti, dove gli stati sono le informazioni su cui opera e le transizioni le istruzioni che li modificano.
Ricapitolando, lo stato di evoluzione della computazione di un processo è l'insieme dei valori di tutte le informazioni da cui dipende l'evoluzione della computazione del processo. Non si limita quindi al solo valore corrente del program counter, ma anche al contenuto delle variabili utilizzate dal programma, dato che una loro eventuale modifica potrebbe portare ad esiti diversi della computazione. Da qui l'importanza che l'esecuzione di un processo non alteri quella di un altro, o riscontrerei evoluzioni diverse da quelle corrette: applicare le stesse operazioni su dati diversi, può non condurre agli stessi risultati.
Stato dei processi
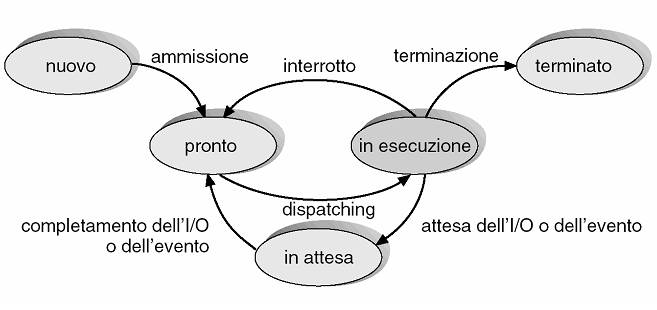
Un processo in esecuzione può assumere diversi stati rispetto all'uso della CPU. Notare bene che non si sta più parlando di stati di computazione, ma stati di uso del processore da parte di un processo, o in breve stati del processo, che rappresentano la modalità di uso corrente del processore e delle risorse da parte del processo.
Ciascun processo può trovarsi in uno dei seguenti stati:
- new (nuovo), se è stato appena creato e inizializzato
- running (in esecuzione), se le istruzioni sono eseguite regolarmente e la computazione evolve effettivamente. In ogni istante, solo un processo per processore può essere in questo stato
- waiting (in attesa), se il processo sta aspettando il verificarsi di qualche evento, ad esempio che gli vengano assegnate delle risorse o il completamento di un'operazione di I/O
- ready-to-run (pronto all'esecuzione), se ha tutte le risorse necessarie allo svolgimento delle sue attività, eccetto la CPU da cui aspetta di essere chiamato. La computazione potrebbe dunque evolvere, ma non lo fa perché le istuzioni non possono essere eseguite dal processore
- terminated (terminato), se ha terminato l'esecuzione e sta aspettando che il sistema operativo rilasci le risorse che utilizzava e lo rimuova dalla memoria (il che non avviene sempre immediatamente).
I nomi dei vari stati non sono definiti univocamente e infatti possono cambiare a seconda del sistema operativo; ciò che rappresentano è invece comune a tutti i sistemi, che al più potranno introdurne altri.
Il diagramma degli stati dei processo è un grafo orientato che rappresenta l'insieme degli stati del processo (i nodi) e le transizioni tra essi (gli archi).
Process control block
Il sistema operativo rappresenta i processi in una struttura dati nota come process control block (PCB, blocco di controllo del processo) o task control block in cui ne vengono memorizzate le principali informazioni. Tra queste, che potrebbero variare a seconda dei sistemi, ricordiamo:
- identificatore del processo, un numero unico e univoco
- stato del processo, considerato in questo caso come stato di uso del processore da parte del processo
- program counter
- registri della CPU, che variano per numero e tipo a seconda dell'architettura del computer. Sono ad esempio i registri indice e altri registri di uso generico
- lo stack pointer
- informazioni per la schedulazione della CPU, che specifica quali tecniche e criteri di schedulazione dovrà operare il processore sul processo
- informazioni per la gestione della memoria centrale
- informazioni per l'accounting
- informazioni sullo stato dell'I/O, che riportano la lista dei file e delle periferiche associate al processo
Non tutte le informazioni sono strettamente necessarie come supporto della gestione del processore, ma vengono comunque inglobate per avere un'unica tabella omogenea a livello di contenuto.
Le PCB relative a ogni singolo processo si riveleranno fondamentali nell'implementazione del multi-tasking.
Cambio di contesto
Se il mio obiettivo è realizzare un sistema multi-tasking, far passare la CPU da un processo all'altro richiede il salvataggio dello stato di evoluzione della computazione del vecchio processo e il caricamento dello stato di esecuzione di quello nuovo, questo perché bisogna garantire che il processo si evolva come se fosse l'unico eseguito dal processore, quindi che nessun altro processo si permetta di toccare le informazioni che definiscono lo stato di evoluzione della computazione. Questa fase è nota come cambio di contesto (context switch), dove per contesto di un processo si intendono alcune informazioni contenute nel suo specifico PCB, come il valore dei registri, il suo stato, lo stack pointer, ecc.
Per quanto riguarda il salvataggio dello stato di evoluzione della computazione, si deve tener conto che:
- di codice del programma, dati del programma, heap e stack possiamo anche non preoccuparci, dato che il sistema operativo garantirà che non vengano toccati da nessun altro processo
- i registri vengono invece utilizzati da tutti i processi, quindi occorre salvarne da qualche parte (generalmente nello stack) il contenuto per poi recuperarli. Salvo tutti i registri o solo quelli che potrebbero essere modificati? Li salvo tutti, per tre buoni motivi:
- per sapere quali registri saranno utilizzati dal processo successivo bisognerebbe eseguirlo, ed eseguendolo perderei tutto, non risolvendo nulla
- anche se fosse possibile conoscere i registri che saranno modificati, ci vorrebbe troppo tempo per copiare uno alla volta quelli necessari (ogni copia corrisponde ad un ciclo fetch-decode-execute). Il tempo perso per il salvataggio dei registri utili va poi moltiplicato per tutte le volte che effettuo una turnazione dei processi in esecuzione, ottenendo rallentamenti spropositati
- la maggior parte dei processori hanno un'istruzione PUSH ALL, che salva in una volta sola i valori di tutti i registri
- lo stack pointer non può essere ovviamente salvato nello stack, o otterrei un salvataggio ricorsivo (per memorizzare l'indirizzo della sua cima deve scrivere in cima, ottenendo un nuovo indirizzo della cima da memorizzare, che... ecc). E' per questo motivo che, come abbiamo visto prima, il suo valore viene memorizzato nel process control block associato al processo
Quando la CPU dovrà riattivare un dato processo, cercherà il suo stack pointer nel PCB relativo e da lì recupererà i valori dei registri e del program counter, così da poter riprendere l'esecuzione da dove l'aveva interrotta.
Per alcuni processi questo sistema può essere critico, a causa dei tempi di gestione delle turnazioni, la cui velocità varia da macchina a macchina (dipende da vari fattori, quali la velocità della memoria, il numero di registri da copiare, ...). I processi in questione sono proprio quelli non performanti per il multi-tasking, ovvero quelli che gestiscono sistemi in tempo reale o che comunque non gradiscono il time sharing.
Sospensione e riattivazione dei processi
Sospendere e riattivare i processi è l'anima del multi-tasking, il cui obiettivo - ricordiamolo - è consentirne la turnazione sul processore massimizzandone lo sfruttamento. Ciò viene realizzato secondo una precisa metodologia:
- sospensione del processo in esecuzione, salvando in modo sicuro lo stato di evoluzione della computazione in modo tale da poter tornare ad eseguire il processo dallo stesso punto in cui l'avevo lasciato
- ordinamento dei processi in stato di pronto (scheduling), per stabilire quale deve essere eseguito per primo
- selezione del processo in stato di pronto da mettere in esecuzione (dispatching), il passo logico successivo allo scheduling
- riattivazione del processo selezionato
Tali operazioni devono tener conto del comportamento dei processi rispetto all'uso delle risorse fisiche, in base al quale li distinguiamo in:
- I/O-bound, che effettuano più I/O che computazioni
- CPU-bound, che effettuano principalmente computazioni (in casi limite potrebbero anche non avere alcuna I/O)
Il sistema che implementerà il multi-tasking dovrà dunque tener conto delle classi dei processi, bilanciandoli opportunamente. Ad esempio, eseguire pochi processi I/O-bound non sfrutterebbe al meglio il processore, dandogli poco e niente da computare; eseguire troppi CPU-bound invece, pur assicurando un uso intensivo della CPU, rallenterà drasticamente il sistema (il processo monopolizza il processore e tutti gli altri non potranno evolvere). Quindi non basta massimizzare lo sfruttamento della CPU, occorre anche che l'evoluzione dei programmi in esecuzioni appaia fluida e parallela all'utente.
Come realizzare allora il sistema? Dobbiamo distinguere tra politiche ("che cosa fare") e meccanismi ("come sarà fatto"). Le prime sono le regole, che sono indipendenti da come verranno poi implementate. Nel nostro caso definiscono quando un processo debba essere sospeso, e con quale criterio si dovrà ordinare la coda dei processi pronti. I meccanismi sono invece l'insieme delle operazioni che realizzeranno la politica.
Più in dettaglio, la politica di sospensione dei processi stabilisce che un processo in esecuzione può essere sospeso in modo implicito, ovvero ad opera dell'ambiente operativo, o esplicito, in cui è il processo stesso che richiama volontariamente l'operazione di rilascio del processore.
Appartengono alla sospensione implicita i seguenti casi:
- quando viene effettuata una richiesta di I/O. E' tipica di tutti i sistemi operativi, e tiene conto dei tempi di attesa legati ai tempi elettro-meccanici di esecuzione della chiamata I/O richiesta
- quando dopo aver creato un sottoprocesso ne attendo la terminazione
Ultima considerazione è che sia la sospensione implicita che quella esplicita sono sincrone rispetto la computazione, con la differenza che la prima avviene in stato supervisor (essendo legata a chiamate di sistema, sarà il sistema operativo a gestirla), mentre la seconda in modalità utente (magari attivata con una trap). Si possono avere anche casi di sospensione asincrona rispetto la computazione, ovvero ad esempio allo scadere del quanto di tempo nei sistemi time sharing, un concetto che affronteremo nel capitolo successivo.
Vediamo ora i meccanismi. La sospensione del processo in esecuzione avviene in due passaggi: l'attivazione della procedura di sospensione (tra quelle elencate prima) ed il salvataggio del contesto di esecuzione, ovvero tutti i registri del processore nello stack e lo stack pointer nel Process Control Block. La riattivazione del processo avviene intuitivamente seguendo la procedura inversa, con il ripristino del contesto di esecuzione.
Il context switching visto nel capitolo precedente è dunque composto da queste due "macro-operazioni" di sospensione del processo in esecuzione e riattivazione del processo da mettere in esecuzione.
Da notare infine che alcuni processori (ad esempio gli x86) possono farlo anche in hardware (c'è un'istruzione apposita che salva il contesto dove indicato), ma a volte farlo in software risulta più veloce.
Time Sharing
Una buona definizione di sistema time sharing è sistema multi-tasking a condivisione di tempo. Ha come obiettivo quello di gestire la turnazione dei processi sul processore in modo da creare l'illusione di evoluzione contemporanea delle computazioni, come se ogni processo avesse tutta la CPU per sé. Fin qui nulla di nuovo rispetto al comune multi-tasking; la differenza sta nell'introduzione del concetto di quanto di tempo e pre-emption. Il quanto di tempo (time slice) è l'intervallo di tempo massimo di uso consecutivo del processore consentito a ciascun processo, così che si abbia una equa ripartizione della CPU; la pre-emption è invece il rilascio forzato del processore, con la sospensione del processo in esecuzione. Ho quindi più processi da eseguire caricati in memoria, la cui turnazione è soggetta alle stesse politiche viste per il multi-tasking con l'aggiunta della possibilità di sospensione asincrona alla computazione, dovuta allo scadere del quanto di tempo.
Il dispositivo che rende possibile la sospensione di un processo ancora in esecuzione allo scadere del time slice, è il Real-time clock (RTC). Esso non è altro che un chip impiantato sulla scheda madre contenente un cristallo di quarzo che viene fatto oscillare in modo estremamente stabile con segnali elettrici. Tali oscillazioni (i cui valori dovrebbero essere riportati sul manuale del calcolatore, e in alcuni casi sono anche programmabili) scandiscono il tempo generando periodicamente delle interruzioni da inviare al sistema operativo.
Il periodo dell'RTC è molto piccolo, e se usassi direttamente il suo valore come time slice il sistema perderebbe più tempo a gestire gli interrupt che ad eseguire i processi (questo fenomeno prende il nome di sovraccarico di gestione dell'interruzione). La soluzione è moltiplicarlo per un opportuno fattore k, così che solo un'interruzione ogni k verrà considerata come termine del quanto di tempo. Il fattore dovrà tener conto di un aspetto importante degli interrupt, cioè che quando il processore ne gestisce uno disabilita la ricezione degli altri. Quindi potrebbe succedere che durante la gestione dell'interruzione di altre periferiche arrivi il segnale RTC ed il processore non se ne accorga. Basterebbe però mantenere il valore dell'intervallo di tempo un po' più basso di quanto si vorrebbe, così da aumentare la frequenza degli interrupt e ridurre statisticamente l'incidenza del problema.
Accenni di schedulazione
Se con la multiprogrammazione è possibile avere più processi caricati in memoria, è grazie al multi-tasking e alla gestione time-sharing che essi possono alternarsi nell'utilizzo della CPU, così che la loro evoluzione possa essere portata avanti in parallelo.
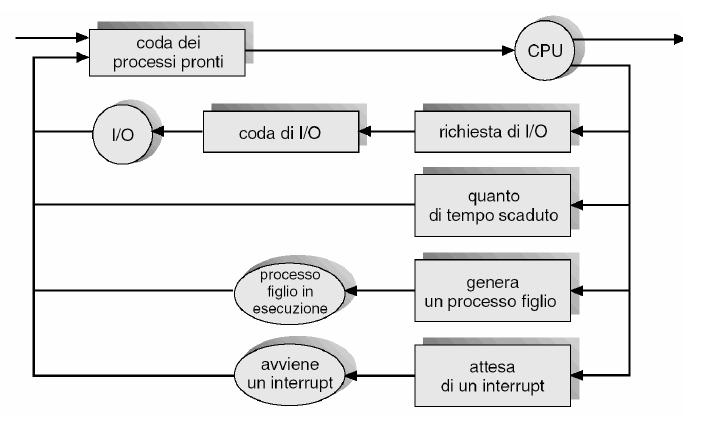
Se ho un unico processore, il sistema non potrà mai avere più di un processo in esecuzione, ed ho quindi bisogno di qualcosa che selezioni i processi pronti all'esecuzione per eseguirli effettivamente sulla CPU, lasciando i rimanenti in attesa. Questo componente prende il nome di schedulatore dei processi (o scheduler), e le strutture da cui acquisisce informazioni sui processi e i lori stati si chiamano code di schedulazione.
Tra le code di schedulazione ricordiamo:
- la coda di lavori (job queue), in cui vengono inseriti tutti i processi del sistema al momento della loro creazione
- la coda dei processi pronti (ready queue), in cui risiedono i processi caricati in memoria centrale che si trovano nello stato ready-to-run. Vi usciranno solo quando saranno selezionati dallo scheduler per l'esecuzione (operazione di dispatching)
- la coda delle periferiche di I/O (device queue), dove vengono inseriti i processi in attesa di una particolare periferica di I/O
Tali code vengono rappresentate con il diagramma delle code, in cui ciascun rettangolo rappresenta una coda, i cerchi le risorse che li servono e le frecce il flusso dei processi nel sistema.
Si può osservare come un processo venga inizialmente messo nella coda dei processi pronti, finché non viene selezionato per l'esecuzione. A questo punto può terminare, o effettuare una richiesta di I/O e spostarsi nella relativa coda, o creare un nuovo processo e attendere che termini, o attendere un interrupt. Quando viene terminato viene rimosso da tutte le code e il suo PCB e le sue risorse vengono deallocate.
Creazione dei processi
Se durante la sua esecuzione un processo volesse creane uno nuovo, può farlo attraverso una chiamata di sistema per la sua creazione e attivazione. Il processo generante prende il nome di padre e quello generato figlio, che a sua volta può generare nuovi figli andando a formare un albero di processi.
Ci sono due considerazioni da fare. La prima è che in seguito alla creazione esistono due possibilità per l'esecuzione dei processi: il padre continua la sua computazione in modo concorrente ai figli, oppure attende che tutti o parte di essi siano terminati. La seconda considerazione riguarda invece la concessione delle risorse ai figli, ovvero decidere se condividerle (tutte o in parte) col padre, fare in modo che siano ottenute direttamente dal sistema operativo, o passare dei dati in input che la inizializzino dopo la creazione.
Prima di vedere come implementare tale funzione nei sistemi Unix, anticipiamo brevemente il concetto di spazio di indirizzamento, cioè quella porzione di memoria centrale riservata al processo dal sistema operativo, alla quale nessun altro processo può accedere (salvo eventuali sincronizzazioni, che per ora non interessano). E' al suo interno che vengono memorizzati il codice e i dati, questi ultimi residenti nelle strutture dati opportune che abbiamo visto nei capitoli precedenti.
Possiamo finalmente vedere la chiamata di sistema per la creazione di un nuovo processo nei sistemi Unix: fork(). Essa produce una copia distinta dello spazio di indirizzamento del padre, ovvero stesso codice del programma e stessi dati al momento della creazione. Il meccanismo di comunicazione tra padre e figlio è particolarmente semplice, ed è reso possibile dal codice di ritorno della funzione fork(), che per il padre è l'identificatore del figlio (il pid, un numero intero maggiore di 0), mentre per quest'ultimo è proprio 0. Di seguito un esempio di codice:
int valore = fork();
if (valore == 0)
{
printf("Sono il figlio!\n");
return (0);
}
else
{
printf("Sono il padre!\n");
return (0);
}
Ma se il processo figlio è una copia esatta del padre (più esattamente, è un duplicato distinto del suo spazio di indirizzamento), come si può allora generare processi indipendenti? Unix mette a disposizione un'ulteriore chiamata di sistema, la exec(), che permette di caricare un nuovo programma nello spazio di memoria del processo che la esegue. Il padre dovrà in pratica lanciare all'interno del processo figlio (quindi, dopo la fork()) una exec() specificando da quale porzione di memoria andare a caricare il nuovo codice e i nuovi dati da sovrascrivere agli attuali.
Pur essendo piuttosto comune che a una fork() segua una exec(), le due funzioni vengono mantenute comunque separate perché potrebbero essere utilizzate singolarmente per altri scopi diversi dalla creazione dei processi. Ad esempio con una exec() potrei cambiare il codice dello stesso processo in esecuzione semplicemente per svolgere attività di tipo diverso.
Terminazione dei processi
Un processo normalmente termina dopo l'esecuzione della sua ultima istruzione, quando chiede al sistema operativo di rimuoverlo tramite la chiamata exit(). Per rimozione dal sistema si intende la deallocazione di tutte le risorse in uso, ovvero le porzioni di memoria occupate, i file aperti e i buffer di I/O. La exit() restituisce un valore di ritorno (tipicamente un intero) dal quale si capisce se l'operazione è andata a buon fine o se ho riscontrato errori.
Esistono altri due motivi per i quali può terminare un processo, entrambi che coinvolgono il padre dello stesso. In un caso ho la cosiddetta terminazione diretta, col padre che decide di interrompere l'esecuzione di un suo figlio per vari motivi (perché ha ecceduto nell'uso delle risorse concesse, perché i suoi servizi non sono più necessari, ...) attraverso la funzione abort(). L'altro prende invece il nome di terminazione a cascata, è messa in esecuzione da alcuni sistemi operativi e consiste nella terminazione forzata di tutti i figli di un processo che (in modo normale o anormale) ha finito la sua computazione. Altri sistemi invece, come ad esempio l'Unix, nel caso in cui un processo termini, assegnerebbero tutti i suoi figli al processo init (il primo processo che il kernel manda in esecuzione dopo aver terminato il bootstrap) così che possano continuare la loro evoluzione.
Torna alla pagina di Sistemi Operativi