Torna alla pagina di Sistemi Operativi
:: Appunti 2.0 ::
Schedulazione
Introduzione
La schedulazione è un'operazione fondamentale dei moderni sistemi operativi multiprogrammati e multi-tasking. La sua funzione è quella di gestire in modo ottimale la turnazione dei processi sulla CPU, definendo delle politiche di ordinamento.
Il suo successo si basa sulla proprietà di ciclicità del processo, che durante la sua esecuzione alterna continuamente fasi di computazione svolte dal processore (picco di CPU) e fasi di attesa di una periferica (picco di I/O), che si concludono con una richiesta di terminazione al sistema. La durata dei picchi del processore variano molto di processo in processo e di macchina in macchina, ma si attesta in media sotto gli 8 millisecondi. In particolare, processi di classe I/O-bound avranno molti picchi brevi della CPU, mentre quelli CPU-bound (con intensa attività computazionale) ne avranno pochi ma lunghi. Questo genere di considerazioni devono essere messe in gran rilievo nella scelta dell'algoritmo di schedulazione.
Esistono due strategie di attivazione della schedulazione, con e senza rilascio forzato.
La schedulazione senza rilascio anticipato è chiamata non pre-emptive: una volta assegnata la CPU ad un processo, questo la tiene finché non avvengono una delle seguenti circostanze:
- quando un processo in esecuzione passa allo stato di attesa (ad esempio, dopo aver chiesto un'operazione di I/O o attendendo il termine di uno dei figli)
- quando un processo in esecuzione passa allo stato di pronto (ad esempio, quando si verifica un interrupt)
- quando un processo rilascia volontariamente il processore
- quando un processo termina
Quando avviene uno di questi casi, viene mandato in esecuzione il processo selezionato dallo schedulatore. La schedulazione non-preemptive è quindi evidentemente sincrona con l'evoluzione dello stato della computazione.
Nei sistemi multi-tasking a condivisione di tempo (time sharing) si rende invece necessaria un'ulteriore modalità di attivazione dello schedulatore, asincrona con la computazione, che corrisponde allo scadere del quanto di tempo concesso al processo in esecuzione. Si parla dunque di schedulazione con rilascio anticipato, o pre-emptive scheduling. Essa non è del tutto indolore, dal momento che può comportare un costo legato all'accesso dei dati condivisi. Ad esempio, si considerino due processi che condividono dei dati: mentre uno li sta modificando, gli scade il time slice e viene terminato forzatamente. Quando l'altro proverà a leggere i dati li troverà in stato inconsistente. Bisognerà dunque trovare dei meccanismi di sincronizzazione per evitare che ciò accada.
Livelli di schedulazione
I sistemi operativi possono schedulare secondo tre modalità, detti livelli di schedulazione, che agiscono appunto su diversi livelli temporali. I nomi stessi sottolineano la loro dipendenza dalla frequenza con cui sono eseguiti, quindi dal fattore tempo; si parla infatti di schedulazione a breve termine, a lungo termine e a medio termine.
La schedulazione a breve termine (anche nota come CPU-scheduler), ha come obiettivo ordinare i processi già caricati in memoria centrale e nello stato ready-to-run. Perché proprio questi? Perché se considerassi anche i processi non attivi dovrei prima caricarli dalle memorie di massa, perdendo del tempo, così come per quelli in stato di wait, che se anche ottenessero l'accesso al processore dovrebbero comunque aspettare il verificarsi dell'evento per il quale sono in attesa.
La schedulazione a breve termine garantisce quindi una turnazione rapida, ed è per questo che viene eseguita frequentemente (almeno ogni 100 millisecondi). L'algoritmo che l'implementa deve quindi essere molto veloce per minimizzare il carico di gestione, o finirei a metterci più tempo a schedulare che ad eseguire; ciò si ottiene con una relativa semplicità del codice, che opera una scelta migliore nell'immediato piuttosto che fare valutazioni più complete ma dispendiose.
La schedulazione a lungo termine (anche detto long-term scheduler o job scheduler) ordina tutti i processi attivati nel sistema, compresi quelli presenti nelle memorie di massa, identificando il gruppo di processi che devono essere caricati in memoria centrale per l'esecuzione e posti nello stato di ready-to-run. Tale gruppo è costruito mescolando processi CPU-bound e I/O-bound in modo da massimizzare lo sfruttamento della CPU. Ci vuole quindi equilibrio: esagerare con i CPU-bound significherebbe sfruttare al meglio il processore, ma annullare le interazioni con l'utente; utilizzare troppi I/O-bound garantirebbe invece una corretta e fluida interazione, ma con tempi di elaborazione eterni.
In alcuni sistemi tale livello di schedulazione è assente o minimale. Ad esempio in un sistema embedded ho sempre tutti i processi caricati in memoria centrale, quindi un job scheduler si renderebbe del tutto inutile. Spesso non lo hanno neanche Unix e Windows, che si affidano quasi esclusivamente al CPU-scheduler, in quanto non è semplice conoscere a priori il numero di processi attivati.
Gli algoritmi sono usualmente lenti e complessi (senza esagerare), perché scegliere la combinazione più ragionevole di processi da caricare dalle memorie ausiliarie per sfruttare al meglio il processore non è affatto un lavoro banale. Deve perciò essere eseguito poco frequentemente (tipicamente una volta ogni qualche minuto) per evitare di socraccaricare il sistema, o non sarebbe più così produttivo.
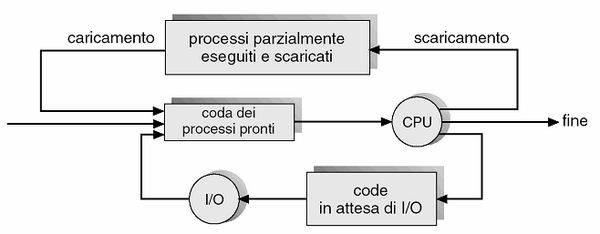
La schedulazione a medio termine (anche nota come mid-term scheduler) si pone a un livello intermedio tra i due precedenti. Viene tipicamente implementato in sistemi operativi come quello con gestione a time sharing, e fa fronte a diversi problemi prestazionali: alta concorrenza per l'utilizzo della CPU, sbilanciamento tra processi I/O-bound e CPU-bound, scarsità o esaurimento della memoria centrale disponibile. Il mid-term scheduler si propone di risolvere tutte queste criticità modificando dinamicamente il gruppo di processi caricati in memoria centrale e posti nello stato ready-to-run dallo schedulatore a lungo termine (riducendo così il grado di multiprogrammazione), al fine di adattarli all'effettiva distribuzione dei lavori che stanno compiendo. In altre parole, corregge gli ordinamenti della schedulazione a lungo termine (che non poteva prevedere tutti gli scenari a priori) in base alla situazione attuale. I processi rimossi dalla memoria centrale vengono spostati in un'area di memoria di massa temporanea, con una procedura chiamata swapping out; il procedimento inverso prende invece il nome di swapping in.
Ecco uno schema che rappresenta tale tipo di schedulazione.
Criteri e metodi di valutazione
Prima di decidere quale tipo di algoritmo di schedulazione della CPU utilizzare, bisogna considerare che ognuno di essi ha caratteristiche che possono favorire una classe di processi piuttosto che un'altra. Esistono diversi criteri per la comparazione degli algoritmi di schedulazione, la cui valutazione preventiva può condurre alla scelta di quello migliore da utilizzare. Di seguito, alcuni criteri:
- utilizzo del processore, ovvero quanto riesco a massimizzarne lo sfruttamento
- frequenza di completamento o throughput, cioè quanti processi riesco a completare nell'unità di tempo (o, per vederla in un altro modo, quanti utenti riesco a soddisfare)
- tempo di completamento (turnaround time), che è l'intervallo di tempo che intercorre tra l'immissione del processo nel sistema e il suo completamento. Non considera solo il tempo di esecuzione, ma anche quello di attesa prima di essere caricato in memoria, quello speso nella coda dei processi pronti e di I/O
- tempo d'attesa del processo nella coda dei processi pronti
- tempo di risposta, più adatto del turnaround time nei sistemi interattivi, che indica l'intervallo di tempo che intercorre tra la formulazione della prima richiesta alla produzione della prima risposta.
In linea teorica è sempre desiderabile massimizzare l'utilizzo della CPU e il throughput, minimizzando quanto possibile il tempo di completamento, di attesa e di risposta; notare come alcuni studiosi suggeriscano di riferirsi più alle varianze di tali parametri che ai loro valori medi.
In pratica bisogna valutare attentamente il carico applicativo e i fattori critici del mio sistema, e in base a questo scegliere un algoritmo di schedulazione che sia un giusto compromesso tra i vari criteri sopra esposti. Ad esempio un server può aver bisogno di quanti di tempo lunghi, perché non deve essere interattivo ma avere tanto throughput; un sistema desktop può invece permettersi di essere meno performante sul lungo periodo, ma deve reagire istantaneamente alle richieste dell'utente.
Per vagliare se gli algoritmi considerati soddisfino i particolari criteri che voglio raggiungere, posso utilizzare diversi metodi di valutazione.
Una delle principali è la valutazione analitica, di cui è un esempio la modellazione deterministica dell'algoritmo, che ne definisce in modo matematico le prestazioni in base a un carico di lavoro predeterminato. Da un punto di vista logico è semplice, veloce e molto precisa; per contro ha però che richiede numeri esatti in ingresso, senza nessun approssimazione, perché piccoli errori sui dati potrebbero ripercuotersi pesantemente nella valutazione delle cifre di riferimento del problema analitico. Ulteriore limite è che i suoi risultati si applicano solo ai casi studiati, non possono essere generalizzati. Proprio per questi motivi la modellazione deterministica viene usata principalmente per la descrizione degli algoritmi di schedulazione e la produzione di esempi.
Se non è possibile creare un modello deterministico, la valutazione statistica mi permette di considerare da un punto di vista probabilistico i valori dei termini di riferimento che mi interessano, quindi con un certo grando di incertezza intrinseca dei dati pur sempre rappresentativi. Un esempio di questo tipo di valutazione sono i modelli a reti di code, in cui il sistema è rappresentato come una macchina che offre un certo numero di servizi diversi (ad esempio l'accesso alla memoria, a un disco, a una periferica, ...). Ogni servizio ha una sua coda di processi e ogni processo, nella sua evoluzione, potrà passare da una coda all'altra; la gestione ottimale dei flussi di richieste sarà obiettivo del sistema, mentre chi compie la valutazione statistica dovrà tener traccia dei vari parametri che caratterizzano le code (frequenza di arrivo e di uscita, lunghezza media, tempi medi di attesa, ...) per ottenere una stima approssimata e verosimile del modello implementato.
Un tipo di valutazione statistica più accurata degli algoritmi di schedulazione è la simulazione, ovvero la realizzazione software del modello del sistema, processi applicativi e schedulatore inclusi, con un certo grado di aderenza alla realtà. Il simulatore consente di modificare le variabili del sistema, tra cui il tempo e il numero e il tipo di processi coinvolti, e monitorarne le prestazioni così da compilare delle statistiche. Pur ottenendo valutazioni piuttosto accurate, le simulazioni possono essere costose perché dovrò perdere tempo a progettarle, codificarle ed eseguirle (più sono precise e più diventano onerose).
Se nemmeno il grado di accuratezza della simulazione mi può bastare, allora non mi resta che l' implementazione come modalità di valutazione. Essa consiste nella realizzazione effettiva del sistema hardware e software, così da poter fugare ogni dubbio sull'incertezza dei risultati. In questo modo è possibile effettuare una scelta dell'algoritmo di scheduling in base alle esigenze e alle caratteristiche reali, raccogliendo le informazioni sul carico di lavoro utilizzando strumenti di rilevazione interni al sistema operativo. Anche questa soluzione comporta però alcuni svantaggi. Uno ovvio è il costo elevato, non solo in termini di sforzi di implementazione dell'algoritmo (e alle modifiche del sistema operativo perché possa supportarlo), ma anche perché comporta la cooperazione degli utenti, a molti dei quali non interessa che lo schedulatore sia più efficiente, ma che i loro processi siano eseguiti correttamente e in tempo utile. Un'altra difficoltà è legata al fatto che il sistema gestisce carichi diversi a seconda del momento della giornata, e quindi potrebbe aver bisogno di scheduling diversi per ottenere il miglior risultato possibile in ogni momento. Si dovrà dunque valutare se usare il trend medio come criterio di valutazione, oppure adattarsi di volta in volta alla nuova situazione.
Algoritmi di schedulazione
First-Come, First-Served
L'algoritmo di schedulazione più semplice è il First-Come, First Served (FCFS), la cui politica è definita nel nome stesso: il processo che chiede la CPU per primo la ottiene per primo. L'implementazione è piuttosto immediata, potendo sfruttare strutture dati come le code FIFO, in particolare la coda dei processi pronti. Quando un processo passa allo stato di ready-to-run, il suo PCB viene collegato alla base della coda; quando invece il processore si libera, il processore in testa alla coda viene rimosso da essa e messo in esecuzione. Se il vantaggio di questa realizzazione è la semplicità di scrittura e lettura, uno dei limiti è rappresentato dal tempo medio di attesa piuttosto lungo. Facciamo un esempio. Ho tre processi: P1 (tempo di elaborazione, in millisecondi: 24), P2 (3) e P3 (3), che arrivano in quest'ordine. Posso visualizzare la situazione con il seguente diagramma di Gantt:

Il tempo di attesa è 0 per P1, 24 per P2 e 27 per P3. Il tempo medio di attesa è pari quindi a 17 millisecondi.
Se invece avessi avuto la seguente disposizione dei processi
i tempi di attesa sarebbero stati 0 per P2, 3 per P3 e 6 per P1, con un'attesa media drasticamente ridotta a 3 ms.
Quello che abbiamo appena visto è un esempio di effetto convoglio, caratterizzato dal fatto che l'evoluzione di più processi brevi è ritardata dall'attesa per la terminazione di un unico processo più lento. Calando il tutto in un situazione reale, potremmo pensare ai processi brevi come I/O-bound, e a quello più lungo come un CPU-bound.
Shortest-Job-First
Anche nel caso del Shortest-Job-First (SJF) il nome rende l'idea che sta dietro all'algoritmo, ovvero che il processo più breve viene eseguito per primo. Tale politica di schedulazione è quella ottimale, poiché fornisce sempre il minor tempo di attesa medio per un dato gruppo di processi. Se infatti eseguo prima i processi più brevi il loro tempo di attesa diminuisce molto più di quanto possa aumentare quello dei processi più lunghi, diminuendo di conseguenza il tempo medio.
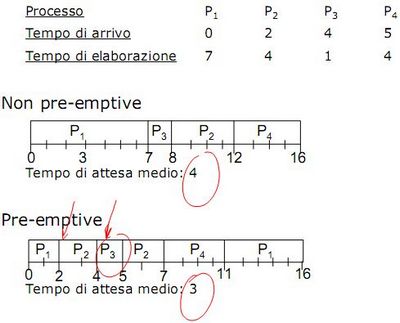
Posso implementare l' SJF sia pre-emptive che non pre-emptive. Come sappiamo, nel primo caso appena un processo diventa pronto interrompe quello in esecuzione richiedendo una schedulazione; nulla di tutto questo nel secondo caso. In generale si dimostra più efficiente il pre-emptive, come si può osservare nell'esempio seguente
La complessità dell'algoritmo sta nel conoscere il tempo di elaborazione di tutti i processi, e non è un'informazione semplice da reperire. Negli schedulatori a lungo termine è possibile utilizzare come valore il tempo limite specificato dall'utente nel momento della richiesta di esecuzione del processo, ottenendo buoni risultati. Ciò non è invece possibile in quella a breve termine, dove non esiste modo di conoscere con certezza il tempo di elaborazione richiesto dai processi. Tuttavia esistono delle tecniche per prevederlo, ad esempio ipotizzando che rimanga simile a quelli precedenti si può supporre che il suo valore sia pari alla loro media esponenziale. Rimane comunque una predizione, con tutte le incertezze che essa comporta; bisogna dunque prestare molta attenzione alle scelte dei valori, o potrei fare più danni che altro.
Schedulazione a priorità
L'algoritmo di schedulazione a priorità assegna una priorità ad ogni processo, dove per priorità si intende una proprietà che indica quanto prima dobbiamo eseguire un processo rispetto ad altri, indipendentemente dall'ordine con cui è arrivato. La SJF non ne è che un caso particolare, in cui la priorità era l'inverso del tempo di elaborazione, ovvero era tanto maggiore quanto minore era il tempo.
Il valore della priorità è espresso generalmente in numeri, memorizzati in un indice associato al processo. E' importante sottolineare come non sia affatto automatico il collegamento "valore alto" -> "priorità alta". Ad esempio nei sistemi Unix più l'indice è basso e più il processo è importante; in particolare i processi di sistema hanno priorità negativa (il minimo è -20) mentre quelli delle applicazioni positiva. Questo tipo di rappresentazione è detto a logica inversa, mentre quella diretta è dei casi in cui a indice alto corrisponde priorità alta.
Ad esempio:
Il tempo di attesa medio è di 8.2 millisecondi.
La priorità può essere definita internamente o esternamente. Internamente, quando come indici vengono utilizzate proprietà misurabili del processo, come il tempo di esecuzione, le risorse impiegate, ecc. Esternamente quando invece sono assegnate con politiche estranee al sistema operativo, come l'importanza del processo o degli utenti che l'utilizzano, o altro ancora.
Come al solito possiamo avere:
- schedulazione pre-emptive. Quando un processo entra nello stato ready-to-run andrà a controllare se il processo in esecuzione ha priorità minore, nel qual caso si sostituirà a lui con una pre-emption. Se invece è running un processo di priorità maggiore, l'ultimo arrivato verrà ordinato secondo i normali criteri di schedulazione per priorità
- schedulazione non pre-emptive, in cui anche se il processo che diventa pronto ha priorità maggiore di quello in esecuzione, non interrompe nulla. Verrà eseguito solo quando l'altro terminerà, e solo se non sono sopraggiunti altri processi ready-to-run di priorità maggiore
Un problema di questo tipo di politica di schedulazione è che processi a bassa priorità potrebbero rimanere ready-to-run per un tempo indefinito; basta infatti che continuino ad arrivare processi a priorità maggiore che gli passino avanti. Questo fenomeno prende il nome di starvation, o blocco indefinito. La soluzione è introdurre un progressivo invecchiamento delle priorità, detto aging. In pratica, se abbiamo un processo che rimane in starvation per un tempo abbastanza lungo, cominciamo ad aumentargli la priorità proporzionalmente al tempo di attesa, sperando che ne acquisisca (e prima o poi succederà) abbastanza priorità da essere eseguito. Una volta ottenuto il suo turno di computazione, il suo livello di priorità viene riabbassato allo stato iniziale, e riprende il ciclo di starvation -> invecchiamento -> computazione. Questa tecnica prevede dunque l'utilizzo di priorità di tipo dinamico, che aumentano con l'invecchiare del processo.
Round-Robin
L'algoritmo di schedulazione Round-Robin (RR) può considerarsi un adattamento del FCFS per i sistemi a condivisione di tempo; funziona infatti come un First-Come, First-Served con l'aggiunta della pre-emption per alternare i processi allo scadere di un quanto di tempo. Lo schedulatore tratta la coda dei processi pronti in modo circolare (quando esaurisce il giro, ricomincia daccapo), assegnando la CPU a ciascun processo per un intervallo di tempo della durata massima del time slice.
A livello implementativo la coda dei processi viene realizzata come una coda FIFO, in cui i nuovi processi vengono aggiunti in fondo. Quando lo schedulatore manda in esecuzione un processo imposta un timer per generare un interrupt dopo il quanto di tempo. A questo punto si possono avere due scenari: o il processo riesce a rilasciare la CPU prima del tempo concessogli, o il timer scatterà e il sistema operativo farà in modo che avvenga un context switch del processo in esecuzione, mettendolo in fondo alla coda dei processi pronti. In entrambi i casi lo schedulatore selezionerà il processo ready-to-run successivo. Naturalmente l'algoritmo usato è pre-emptive, dal momento che nessun processo può essere eseguito per più di un quanto di tempo successivo (a meno che non sia l'unico pronto).
Un esempio:
Se il time slice dura 4 millisecondi, ho la seguente situazione
con un tempo di attesa medio pari a 5.66 millisecondi.
Le prestazioni del Round-Robin non sono entusiasmanti, e dipendono molto dalla durata del time slice. Se questo è troppo grande si otterrebbe di fatto un FCFS, con tutti i limiti che ne derivano; se al contrario è troppo breve si ottiene la cosiddetta condivisione del processore, che dà ad ognuno degli n processi del sistema l'impressione di essere l'unico eseguito su un processore con 1/n capacità computazionale. Quest'ultima situazione comporta però un sovraccarico della gestione del sistema, dovuto ai frequenti cambiamenti di contesto.
Bisogna dunque riporre molta attenzione nella scelta del valore del quanto di tempo, non dovendo essere né troppo alto né troppo basso. A tal fine esiste una regola empirica che raccomanda di fare in modo che l'80% delle richieste di elaborazione riesca ad essere completata in un quanto di tempo. Generalmente tale valore si attesta tra i 10 e i 100 millisecondi.
Per concludere, un'ultima considerazione sulla velocità di esecuzione dei processi e sul turnaround. I primi sono strettamente collegati al numero di processi pronti, mentre i secondi dipendono fortemente dalla durata del time slice.
Coda a più livelli
Se sono presenti nel sistema molti processi di tipo diverso si può provare a raggrupparli per tipologie omogenee, così da applicare ad ognuna di esse l'algoritmo di schedulazione più performante. Ad esempio, una classificazione comune distingue i processi eseguiti in foreground (quelli più interattivi, magari schedulati con un RR) da quelli in background (che agiscono sullo sfondo, per i quali si potrebbe utilizzare un FCFS). L'algoritmo di schedulazione con coda a più livelli (C+L) permette tale gestione, partizionando le code dei processi pronti in più code di attesa separate, ognuna col suo specifico algoritmo di schedulazione. I processi sono assegnati in modo permanente a una sola coda, scelta in base a qualche proprietà intrinseca come la dimensione di memoria, la priorità o altro.
Le code sono a loro volta schedulate da un algoritmo dedicato, usualmente di tipo pre-emptive a priorità fissa. Ad esempio potrei progettare un algoritmo di schedulazione con coda a più livelli, con quattro code, che suddivide i processi nelle seguenti tipologie:
- di sistema
- interattivi
- batch
- degli studenti
Ogni coda ha priorità maggiore di quella sottostante, e viceversa. Ciò significa che non potrà essere eseguito nessun processo nella coda dei batch se prima non si siano svuotate le code dei processi di sistema e di quelli interattivi.
Le code potrebbero schedulate anche per partizionamento di tempo, ad esempio assegnando una certa quantità di tempo di CPU a ognuna di esse. Riprendendo il primo esempio, potrei assegnare l'80% del tempo ai processi foreground, e il rimanente 20% a quelli in background.
Coda a più livelli con retroazione
La schedulazione con coda a più livelli con retroazione (C+LR) permette ciò che la C+L non consentiva, ovvero che un processo possa muoversi tra le code di schedulazione. Ciò rende la struttura più flessibile, adattandola all'uso dinamico del processore da parte dei processi. Se ad esempio un processo utilizza per troppo tempo la CPU, c'è il rischio di starvation per tutti i processi delle code a priorità più bassa; si attua dunque una politica di degradazione, ovvero lo si sposta nella coda di schedulazione di livello inferiore. Analogamente, se un processo attende troppo a lungo che sia eseguito, verrà attuata una politica di promozione che lo sposterà in una coda a priorità più alta. Questo schema tende a spostare i processi interattivi e I/O-bound nelle code superiori, in una sorta di processo di invecchiamento dinamico che previene il fenomeno della starvation.
Ricapitolando, per definire lo schedulatore con coda a più livelli con feedback, oltre a specificare il numero di code e il tipo di algoritmo di schedulazione applicato su ognuna di essa, è necessario sapere quando implementare la politica di promozione e degradazione dei processi, e quale politica di allocazione attuare (ovvero, in quale coda dovrà entrare un processo quando avrà bisogno di un servizio).
Il C+LR, pur essendo il più completo e configurabile tra i vari algoritmi di schedulazione, è anche il più complesso di tutti.
Schedulazione per sistemi multiprocessore
La schedulazione è un'operazione strettamente vincolata al sistema di elaborazione in uso, e quando viene applicata a sistemi multi-processore la sua progettazione va affrontata in modo diverso, più complesso. Bisogna anzitutto considerare le caratteristiche dell'architettura del sistema:
- se i processori sono equipollenti (identici dal punto di vista funzionale) vengono detti omogenei; se ognuno di essi è invece specializzato per una funzione diversa, si parla di processori eterogenei. Nella nostra trattazione ci concentreremo sui primi
- la memoria può essere condivisa o meno
- le periferiche possono essere accessibili indistintamente da tutti i processori, o solo da alcuni
Questi fattori condizionano fortemente la scelta dell'algoritmo di schedulazione, vediamo in che modo.
In sistemi con processori omogenei e memoria e periferiche condivise possiamo attuare una politica di suddivisione del carico (load sharing), fornendo una coda separata per ciascun processore. In questo modo potrebbe però succedere che la coda di un processore rimanga vuota e quindi questo non computi; si previene il fenomeno utilizzando un'unica coda dei processi pronti per tutte le CPU, che vengono schedulati sulla prima che si libera. Da considerare però che tutti i processori leggono dalla stessa memoria, e quindi potrei subire tracolli sul suo bus a causa del sovraccaricamento.
Il load sharing è possibile anche se i processori hanno memoria locale oltre a quella condivisa. Ciò è possibile perché spostare un processo da un processore all'altro comporta anche lo spostamento del suo spazio di indirizzamento. In questo caso devo però tener conto del costo (tempo e spazio) di trasferimento, che nel caso precedente non c'era.
Se ho processori che condividono tutto tranne le periferiche (non per come sono realizzati loro, ma per l'assenza di un bus che li colleghi), va creata una coda relativa alla periferica a cui solo quella CPU ha accesso. Se poi oltre alle periferiche anche le memorie sono locali, allora si avranno code per ogni entità non condivisa, con gli immaginabili problemi di gestione che ne conseguono.
Un caso particolare è quello dei processori eterogenei, in cui esistono code per ogni processore e, sopra di esse, una coda per ogni gruppo di processori omogenei.
Concludendo, indipendentemente da omogeneità o eterogeneità dei processori, il multiprocessamento può essere di due tipi:
- asimmetrico, in cui il sistema operativo (quindi tutte le decisioni di schedulazione, di attività di I/O e le altre attività di sistema) sono eseguite da un singolo processore, definito master, e tutti gli altri pensano solo a eseguire i processi applicativi
- simmetrico, dove ogni processore esegue il sistema operativo e i processi applicativi, che in questo caso saranno schedulati da lui stesso.
Schedulazione per sistemi in tempo reale
I sistemi in tempo reale (real-time) sono quelli in cui il tempo è un fattore critico, ovvero dove la correttezza del risultato della computazione dipende dal tempo di risposta. Per descrivere le politiche di schedulazione di tali sistemi bisogna distinguere tra sistemi in tempo reale stretto e in tempo reale lasco.
Nei sistemi in tempo reale stretto (hard real-time) deve essere garantito il completamento di un'operazione critica entro un certo intervallo di tempo. Per vederla sotto un'altra angolazione, bisogna fare in modo che un processo termini la sua computazione entro un tempo massimo garantito dalla sua attivazione.
Esistono diverse tecniche di scheduling:
- quando un processo viene avviato, gli viene associata un'informazione sulla quantità di tempo entro il quale deve essere terminato o deve eseguire un I/O. Lo schedulatore dovrà fare una stima del tempo di elaborazione, e solo se riuscirà a garantire la terminazione del processo lo accetterà e gli prenoterà le risorse necessarie. Questa garanzia si chiama resource reservation e presuppone che lo schedulatore conosca con precisione i tempi di esecuzione di ogni funzione del sistema operativo, il che non è banale (basta che ci siano memorie secondarie o virtuali perché tali stime diventino imprecise).
- se i processi sono periodici, posso associare ad ognuno di essi tre informazioni: il tempo fisso di elaborazione t una volta ottenuta la CPU, una scadenza d entro cui deve essere servito e il suo periodo p. La relazione tra queste grandezze è: 0 <= t <= d <= p. Posso sfruttare queste proprietà facendo sì che il processo dichiari allo schedulatore la frequenza 1/p e la propria scadenza, imponendo che uno dei due valori sia considerato come priorità. L'algoritmo di schedulazione applica poi una tecnica di controllo dell'ammissione, che verifica la possibilità di completamento entro la scadenza dichiarata con la politica di schedulazione descritta.
- anche lo scheduling a frequenza monotòna si applica ai processi periodici, ed è un'estensione della politica precedente con l'aggiunta di pre-emption. La priorità viene stabilita in modo inversamente proporzionale al periodo, quindi è maggiore nei processi più frequenti, e si assume che il tempo di elaborazione di un dato processo Pi rimanga uguale ad ogni accesso alla CPU. Ad esempio, ho due processi P1 (periodo: 50 ms ; tempo elab: 20 ms) e P2 (100 ms ; 35 ms). Essendo più frequente, P1 viene eseguito per primo e completa la sua elaborazione a 20 ms. Subentra P2, che però non riesce a completare la sua: dopo 30 ms (quindi tempo complessivo: 20 + 30 = 50 ms , ovvero il periodo di P1) l'altro processo a priorità maggiore lo scalza e computa per altri 20 ms. Nel suo turno, P2 dovrà essere eseguito per quei 5 ms che gli mancavano, terminando dopo 75 ms dall'inizio, e quindi stando dentro il suo periodo (di 100 ms).
L'algoritmo è considerato ottimo perché se non riesce a schedulare lui, non riuscirebbe a farlo nessun altro algoritmo con priorità statiche in ambiente hard real-time. Ciononostante, l'utilizzo del processore è piuttosto limitato.
- l'algoritmo di schedulazione a scadenza più urgente (Earliest-Deadline First, EDF) si può applicare sia su processi periodici che non periodici, e anche su quelli con tempo di elaborazione variabile. Come politica assegna dinamicamente le priorità a seconda delle scadenze dei processi (che devono dichiararle): prima è la scadenza, più alta è la priorità. Ho quindi una proporzionalità inversa, 1/d. Si dice che l'assegnamento è dinamico, perché quando un processo diventa ready-to-run le priorità di tutti gli altri processi nel sistema possono essere modificate per riflettere la scadenza del nuovo rispetto a quelli già presenti.
Nei sistemi in tempo reale lasco (soft real-time) la computazione è meno restrittiva, dal momento che richiede solo che i processi critici ricevano maggiore priorità di quelli meno importanti. Implementare tali funzionalità richiede in primo luogo operare una distinzione tra processi critici e non, stabilendo che i primi siano quelli real-time e che abbiano priorità statica (il che si ottiene facilmente impedendo l'aging). I secondi sono tutti gli altri processi, su cui è eventualmente possibile applicare una schedulazione a priorità dinamica per evitare fenomeni di starvation. Si rende poi necessario ridurre quanto possibile la latenza del dispatch, ovvero il tempo che intercorre tra lo stato ready-to-run e il running. Un sistema potrebbe ad esempio introdurre dei pre-emption point nelle chiamate di sistema particolarmente lunghe, ovvero dei punti di sospensione in cui viene controllato se un processo a priorità più alta deve essere eseguito. Dato però che metterne molti è poco pratico (c'è da considerare che vanno messi in punti sicuri), la latenza di dispatch può essere comunque lunga anche quando vengono utilizzati. Un'altra tecnica più radicale è rendere tutto il kernel interrompibile, proteggendolo per quanto possibile con meccanismi di sincronizzazione.
Ultima considerazione va fatta sul problema dell' inversione di priorità, ovvero quando un processo che deve leggere o modificare dati del kernel che sono in quel momento utilizzati da altri a più bassa priorità, deve attendere che questi abbiano finito. Ciò è facilmente risolvibile introducendo il protocollo di ereditarietà, in base al quale viene stabilito che tutti i processi che stanno accedendo alle risorse necessarie per un processo a più alta priorità, ereditano momentaneamente tale priorità finché non terminano la computazione.
Schedulazione dei thread
I concetti e le problematiche affrontate finora sono applicabili sia alla schedulazione dei processi che a quella dei thread; in particolare, per questi ultimi vanno fatte alcune considerazioni. Pur essendo mappati tra loro, esiste una separazione netta tra thread a livello utente e quelli a livello kernel (indipendentemente dall'utilizzo di processi leggeri). Ciò comporta due livelli di schedulazione:
- a livello di processo, in cui il processo farà uso di uno schedulatore presente nella libreria dei thread a livello utente. Si parla di process-contention scope (PCS, visibilità della competizione tra processi), dal momento che la competizione per il processore avviene tra thread dello stesso processo. In linea di principio può essere usata qualsiasi politica di schedulazione, anche se è preferibile usare quelle tipiche come il FCFS, il RR o a priorità.
- a livello di sistema, per selezionare quale kernel thread debba effettivamente ottenere l'accesso alla CPU. In questo caso di parla di system-contention scope (SCS, , visibilità della competizione sul sistema) ed è gestita dallo schedulatore del sistema operativo.
Torna alla pagina di Sistemi Operativi




