Torna alla pagina di Sistemi Operativi
:: Appunti 2.0 ::
Thread
I processi tradizionali sono programmi in esecuzione con un unico flusso di controllo. Ognuno di essi è un'entità autonoma, ciascuna con il proprio spazio di indirizzamento inaccessibile agli altri. Ma se questa proprietà da un lato garantisce integrità e sicurezza, dall'altro può rappresentare un problema, soprattutto per quelle applicazioni ad alta disponibilità di servizio e basso tempo di risposta (come i server web), dove l'utente - o gli utenti - potrebbero richiedere l'esecuzione di più flussi di controllo nello stesso processo per attività simili.
Ad esempio ho un server web che accetta le richieste concorrenti di più client per le pagine web e tutti gli oggetti in esse contenute. Se fosse eseguito come un singolo processo riuscirebbe a servire un solo client per volta, facendo lievitare i tempi di attesa di tutti gli altri.
Una soluzione semplice potrebbe essere attivare tanti processi che erogano il servizio quante sono le richieste per lo stesso (ovviamente stiamo parlando di sistemi multiprogrammati e multitasking), ma anche in questo caso avrei svantaggi piuttosto rilevanti. In primo luogo sarebbe impossibile prevedere a priori il numero di richieste di accesso, e quindi quanti processi dovrò attivare. In secondo luogo avrei un sistema lento, con una gestione poco furba delle risorse. Se infatti al server web arrivassero più richieste per una stessa pagina, ogni volta il processo di servizio dovrebbe leggerla e inviarla al client, sprecando tempo e spazio.
Sarebbe dunque bello se operazioni simili su dati diversi operassero in modo più correlato, magari su un'area di memoria centrale condivisa a cui i processi possano accedere in modo nativo e naturale. In particolare, vorrei che le applicazioni rendessero disponibili i propri dati ai processi figli in modo semplice, senza doverli ogni volta ricopiare nei rispettivi spazi di indirizzamento, perché è una soluzione inefficiente.
E' sulla base di queste necessità che nascono i thread, ovvero un gruppo di flussi di esecuzione autonomi sullo stesso programma che accedono alla stessa porzione di memoria centrale. Detto in altre parole, è un mini-processo che vive all'interno di un processo vero, autonomo dal punto di vista dell'esecuzione, ma con la stessa "base di dati" a cui attingere, ovvero quella del processo che lo ha generato.
Il thread può essere anche considerato come l'unità base dell'utilizzo della CPU, e comprende un identificatore, un program counter, un set di registri e uno stack, e condivide con gli altri thread che appartengono allo stesso processo la sezione di codice, quella dei dati e altre risorse del sistema operativo (ad esempio i file aperti).
Se il processo tradizionale (detto pesante) ha un solo thread che fa tutto, un processo multithread è caratterizzato da più flussi di esecuzione di istruzioni in parallelo, operanti contemporaneamente e con parte delle informazioni condivise in memoria centrale. In questo modo ogni thread svolgerà le proprie operazioni e potrà eventualmente trasmetterne i risultati a flussi diversi della computazione, proprio in virtù della condivisione dell'accesso allo stesso spazio di indirizzamento. Ovviamente andranno sincronizzati opportunamente, o potrei avere dati inconsistenti (perché ad esempio modificati da altri).
Un processo multithread è rappresentato nella figura sottostante.
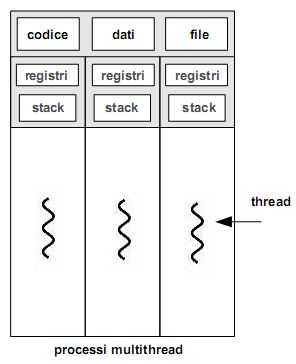
Si può notare come, pur avendo in comune lo stesso codice, due thread diversi hanno comunque contesti specifici su cui operare (quindi registri e stack separati), in modo da poter eseguire operazioni diverse prese da parti diverse del codice. Se infatti condividessero anche stack e registri, finirebbero inevitabilmente per eseguire le stesse operazioni nello stesso momento.
I benefici della programmazione multithread sono i seguenti:
Il supporto per i thread può essere realizzato a due livelli:
Ora che abbiamo distinto thread a livello utente e a livello kernel dobbiamo chiederci come possono essere messi in relazione tra loro, ovvero che modelli multithread sono realizzabili.
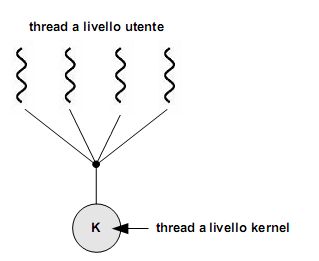
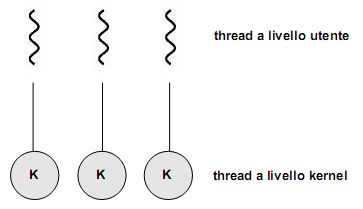
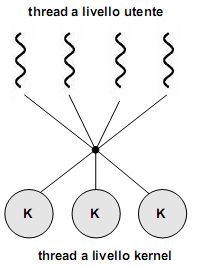
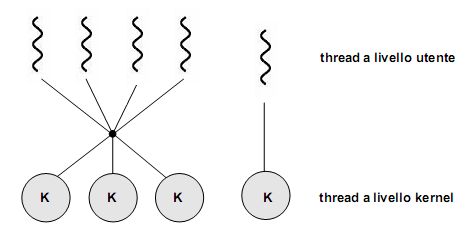
Va da sé che questi modelli si applicano su sistemi multithread. In un sistema operativo con supporto per soli processi pesanti, occorre simularli a livello utente all'interno di un processo utilizzando una libreria di livello utente.
La cooperazione tra più thread può essere rappresentata secondo tre modelli di comportamento:
Vedremo ora le varie funzioni messe a disposizione per la gestione dei thread.
La sintassi della chiamata di sistema per creare un nuovo thread è uguale a quella dei processi, ovvero fork(). La semantica cambia invece sensibilmente. Il problema è il seguente: se il thread di un programma chiama una fork(), verrà creato un nuovo processo con la copia di tutti i thread, o un processo pesante composto da quell'unico thread che aveva lanciato la fork? Dipende dal sistema operativo. Ad esempio nei sistemi Unix viene data la possibilità di scegliere tra le due alternative fornendo due funzioni fork() distinte: quella che duplica tutti i thread e quella che duplica solo il thread che effettua la chiamata di sistema.
La funzione di esecuzione exec() riveste il thread di un nuovo codice, rimpiazzando quello di partenza. In questo caso oltre la sintassi rimane invariata anche la semantica rispetto alla corrispondente chiamata di sistema per i processi.
A questo punto diventa più semplice decidere quale tipo di fork() andare ad eseguire:
exec() subito dopo la fork(), allora quest'ultima potrà essere benissimo quella che duplica il solo thread chiamante, dato che la prima operazione che eseguirà sarà cancellare sé stesso e caricare qualcos'altro
exec() dopo la fork(), allora sarebbe più opportuno duplicare tutti i thread del processo padre.
Quindi, perché due thread appartenenti a uno stesso processo possano eseguire operazioni diverse, posso adottare due strategie: faccio delle call() a porzioni diverse del codice condiviso, oppure utilizzo le exec().
Cancellare un thread significa terminarlo prima che abbia completato la sua esecuzione, ad esempio in un browser web quando clicco sul pulsante di interruzione del caricamento della pagina.
Il thread che sta per essere cancellato viene spesso chiamato thread target, e la sua cancellazione può avvenire in due modalità:
Se ho due processi che lavorano insieme ed ho un thread che vuole comunicare con l'altro processo, la comunicazione può avvenire con tutti i thread del processo destinatario, con un loro sottoinsieme o con uno specifico.
Abbiamo visto come nel modello multithread molti-a-molti (così come in quello a due livelli, di cui è una variante) i thread a livello utente vengano mappati su un numero inferiore (o al più uguale) di kernel thread. Diventa dunque opportuna una coordinazione tra kernel e libreria dei thread, effettuando una loro schedulazione in modo da aggiustarne dinamicamente il numero nel kernel, migliorando così le prestazioni complessive del sistema.
Se il kernel supporta nativamente tale schedulazione non ci sono problemi, ma in caso contrario? Una soluzione potrebbe essere "mascherare" i thread da processi, così che il sistema operativo possa sfruttare gli algoritmi che già conosce e implementa per ottenere il multi-tasking. E' a questo scopo che in molti sistemi sono state introdotte delle strutture dati intermedie fra i thread a livello utente e quelli a livello kernel, detti processi leggeri (lightweight process, LWP). Dei processi essi detengono tutte quelle caratteristiche che lo rendono autonomo e passibile di context-switching, così da potervi applicare la schedulazione; non ha però un proprio spazio di indirizzamento, condividendo di fatto gran parte della memoria con gli altri thread (livello utente). Sull'altro livello, l'LWP appare alla libreria dei thread utente come una sorta di processore virtuale grazie al quale l'applicazione può schedulare l'esecuzione di un thread utente. Va infine ricordato che la mappatura "thread utente - processo leggero" segue il modello uno-a-uno.