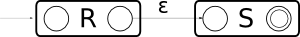Torna alla pagina di Traduttori
:: Traduttori - Appunti del 26 marzo 2009 ::
FA e Regexp
Dopo aver a lungo blaterato sugli automi, vogliamo ora dimostrare che essi sono equivalenti alle espressioni regolari. In termini matematici, quello che vogliamo dimostrare è che
L(A) = L(R), con gli L definiti sullo stesso alfabeto
Intuitivamente, si fa così
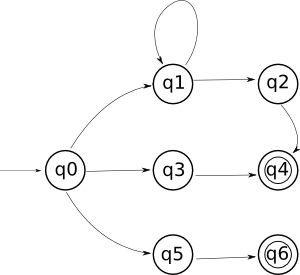
Prendiamo questo automa:
Le trasformazioni intuitive sono queste:
- quando ho diversi archi uscenti da uno stato, allora nella regexp equivalente avrei un'alternativa, cioè un +
- il cammino singolo da uno stato ad un altro è la concatenazione
- un loop è l'operatore *
Possiamo dire che ogni cammino che va dallo stato iniziale ad uno finale viene espresso tramite una regexp, e che poi tutte queste regexp vengono messe in alternativa l'una con l'altra. Un sistema un po' brutale, ma funziona.
Induttivamente, invece, si fa così
Più matematicamente, per ottenere la mia trasformazione da FA a regexp, dobbiamo utilizzare i seguenti concetti:
- |QA| = n, il che vuol dire che l'insieme degli stati del mio automa A li etichetto con dei numeri interi, e questo trucco mi serve per avere comodità a fare certe cose
- R(k)i,j è la regexp che descrive tutte le stringhe w tali che w è contenuta nel cammino che va dallo stato i-esimo allo stato j-esimo (ecco perché li abbiamo appena numerati, così possiamo riferirci a loro con dei numeri). In pratica, questa regexp rappresenta il sotto-automa che parte dallo stato i ed arriva allo stato j, ed in più ho la condizione che gli stati intermedi di questo cammino avranno tutti un indice minore di k.
Ricapitolando: ho preso tutti gli stati, e li ho numerati da 1 ad n. Poi, ho definito la generica regexp R(k)i,j dicendo che rappresenta la porzione di automa che va da i a j, e che in questa strada non passa per stati che nella mia numerazione hanno un indice maggiore di k.
A che cosa mi serve il vincolo su k? Il suo scopo è unicamente permettermi di definire induttivamente la R, in modo piuttosto semplice. Non c'è una profonda verità matematica o logica, è solo un escamotage per facilitarmi nella dimostrazione dell'equivalenza.
Caso base: k = 0
Per come ho appena definito il vincolo su k, dire che k = 0 vuol dire non si deve passare per stati intermedi che abbiano indice > k. Ma k = 0, e quindi non ci sono stati intermedi.
Sono due le occasioni in cui non ho stati intermedi:
- j segue immediatamente i: i -> j, e non ci sono stati intermedi
- i coincide con j, e a maggior ragione non ci sono stati intermedi.
Se j segue immediatamente i, allora come è definita la R(0)i,j? Beh, dipende:
- se non c'è nessun carattere a che porta da i a j, allora R(0)i,j = ∅
- se esiste un solo carattere a che porta da i a j, allora R(0)i,j = a, molto banalmente
- se esistono diversi a che mi conducono da i a j, allora altrettanto banalmente ho R(0)i,j = a1 + a2 + a3 + ... ar
Ricordate che sopra abbiamo detto che, intuitivamente, diversi archi uscenti diventano un'alternativa? Ecco, questa qui sopra ne è la dimosstrazione.
Se invece i = j, allora com'è invece la R(0)i,j?
La prima cosa da dire è che le regole qui sopra valgono ugualmente, perché non c'è nessuna controindicazione.
Tuttavia, di tutte le possibili eventualità, manca quella in cui non c'è nessun arco uscente. In questo caso, dovrei dire che
R(0)i,j = ∅ + ε
Ma allora riformulo anche le altre includendo l'eventualità della stringa ε, e dico pertanto che
- nel caso di un solo arco uscente, ho R(0)i,j = a + ε
- nel caso di più archi uscenti ho R(0)i,j = a1 + a2 + a3 + ... ar + ε
Ho quindi un bel caso base da cui partire.
Passo induttivo: R(k)i,j con k ≠ 0
Anche in questo caso devo sdoppiare la mia dimostrazione:
- posso infatti passare per nessuno stato k
- oppure passare per uno o più stati k
Chiamo "stati k" gli stati con indice maggiore di k bla bla bla.
Se non passo per nessuno stato k, allora vuol dire che tutti gli stati che attraverso avranno indice minore di k. Posso allora dire che:
R(k)i,j = R(k-1)i,j
proprio perché posso abbassare la "soglia".
Se invece passo per uno o più stati k, avrei una situazione di questo tipo:
i -> ... -> k -> ... k-> ... -> j
dove i tre puntini ... dicono che c'è una successione di stati non meglio identificati.
Ho quindi due cammini: uno che va da i a k, e l'altro che va da k a j.
Che cosa succede alla parte in mezzo? Anche qui posso duplicare la risposta:
- posso avere una sola occorrenza di stati k
- posso avere diverse occorrenze di stati k
Ricapitolando, il cammino che va da i a j, con k come limite si può dividere in queste parti:
- vado da i a k, e posso anche abbassare il limite a k - 1 (infatti il limite vale sugli stati intermedi e non su quelli finali o iniziali)
- poi ho tutte le parti in mezzo che vanno da k a k, in cui anche qui posso abbassare il limite a k -1 per analoghe considerazione
- poi ho i cammini che vanno da k a j, ed anche qui posso abbassare il limite a k -1
- infine, c'è anche l'eventualità che non si attraversino stati k
Tutti questi 4 punti possono essere tradotti in regexp, ed il risultato è questo:
R(k)i,j = R(k-1)i,k (R(k-1)k,k)* R(k-1)k,j + R(k-1)i,j
Come avrete notato, i primi tre punti li ho concatenati, mentre l'ultimo punto l'ho messo come alternativa.
Il fatto che ad ogni passo ottengo k-1 mi permette di dire che, se anche partissi da R(n)i,j, alla fine arriverò sempre ad un caso base (ad ogni passo tolgo 1 etc. etc finché non arrivo a 0), e pertanto la costruzione della mia regexp sarà induttivamente corretta.
Un metodo un po' più furbo
Il sistema che abbiamo visto sopra, che potete realizzare seguendo anche solo la descrizione intuitiva dello stesso, non è furbissimo, perché ci saranno un sacco di stati intermedi in cui tutti i cammini passeranno, e siccome la mia costruzione della regexp prevede di concatenare il tutto, mi ritroverò a concatenare mille volte lo stesso stato. L'equivalenza è garantita, ma l'efficienza no.
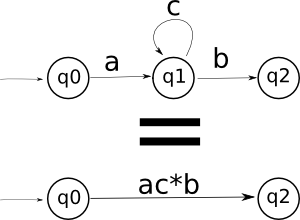
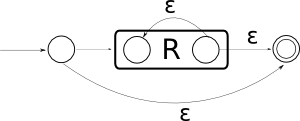
Però possiamo adottare questo stratagemma, esemplificato in questo diagramma:
Vista la magia? Etichetto l'arco con una regexp direttamente! Il sistema in uso è sempre quello di sopra: più archi uscenti diventano un'alternativa, i loop diventano * e i cammini si concatenano. Ma in questo modo riesco ad evitare di costruire stati inutili. Passo passo, parto da un FA ed arrivo alla mia regexp ben pulito, avendo ottenuto una singola regexp per ogni cammino che porta dallo stato iniziale ad uno finale.
Da Regexp a FA
Ora vogliamo fare il passo inverso, ovvero prendere una regexp e ricavarne l'automa. D'altro canto, quando ad esempio in un programma di videoscrittura facciamo una ricerca tramite regexp, il software esegue proprio questa conversione e dà in pasto all'automa così generato i caratteri del testo. Il procedimento di dimostrazione sarà sempre la solita beneamata induzione.
Caso base: ∅, ε e a intese come regexp singole.
Non c'è molto da dire:
- la ε diventa una ε-mossa
- il ∅ non diventa nessun arco, proprio perché è l'insieme vuoto
- la a diventa un arco etichettato con a
Passo induttivo: R + S, RS, R*
R e S sono le mie due regexp. Abbiamo definito la trasformazione delle regexp base nel caso base, e ora procediamo induttivamente con i casi più impestati.
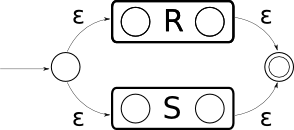
R + S si traduce così:
RS si traduce così:
R* si traduce così:
Questi sono i mattoncini che vengono utilizzati per scomporre passo passo una regexp, e costruire un FA equivalente. Poi, se vogliamo in modo particolare un DFA, allora provvediamo a de-indeterminizzare questo automa, a levare le ε-mosse e così via. Ma tanto sappiamo che sono tutti equivalenti. Bisogna solo stare attenti a concatenare le cose per bene: nelle figure qui sopra, i rettangoli rappresentano delle regexp già fatte. Poi, ricorsivamente, andrò a scomporre anche loro etc. etc. fino a che non ottengo un bell'automa.
Equivalenza tra grammatiche regolari ed automi
Il nostro giro nel mondo delle equivalenze non è ancora finito. Ora vogliamo vedere in che modo è possibile dimostrare l'equivalenza tra grammatiche regolari ed automi.
In particolare, voglio passare da A = (Q, Σ, δ, q0, F) a una G = (NT, T, S, P).
Definisco la G in questo modo:
- NT = Q, cioè l'insieme dei simboli non terminali viene costruito con l'insieme degli stati dell'automa;
- T = Σ, il che vuol dire che i simboli terminali sono l'alfabeto dell'automa;
- S = q0, cioè l'assioma della grammatica è, prevedibilmente, il mio stato iniziale.
Il passo successivo consiste nel convertire la δ in regole di produzione.
In generale si avrà δ = (qi, ak) = qj, cioè passo da un certo stato con un certo input in un altro stato.
- se qj non appartiene agli stati finali, allora qi::= akqj
- se qj appartiene agli stati finali, allora qi::= ak
L'idea è piuttosto intuitiva: se dal mio stato parte un arco che porta in un altro stato non finale, allora devo mettere nella regola il nome di quello stato, che abbiamo visto essere diventato un NT. Se invece quell'input mi porta in uno stato finale, metto nella regola direttamente il simbolo dell'alfbeto che lì mi conduce.
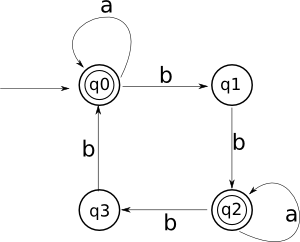
Vediamo un esempio:
Ed ecco le regole con relativa spiegazione.
q0::= a | aq0 | bq1
Dallo stato q0 infatti posso andare in uno stato finale (q0 stesso) con a, che quindi è un simbolo terminale. Ma è un loop, e quindi devo anche prevedere di poter tornare su me stesso, ed ecco perché metto anche aq0. Infine, posso andare in qq con b.
q1::= bq2 | b
Da q1 mi sposto solo con b. Se arrivo in q2, potrei aver terminato, ma siccome anche q2 ha delle frecce che escono, allora devo considerare anche l'eventualità di non fermarmi in q2.
q2::= bq3 | a | aq2
Il ragionamento è analogo: con la b vado in q3, che non è finale, e quindi è un NT. Con la a rimango in q2, ma posso rimanerci sia per concludere che per proseguire, ed ecco perché ho sia a che aq2.
q3::= bq0 | b
Abbiamo capito il giochetto, e qui non facciamo eccezione.
Attenzione ad una cosa importante: in generale gli automi accettano senza problemi anche le ε, mentre le grammatiche NO! O meglio, le grammatiche 0 e 1 sì, mentre quelle regolari no.
Da grammatica regolare ad automa
L'ultimo passo di conversione è quello che ci porta da una grammatica regolare G ad un FA. Ci sono delle semplici condizioni di conversione:
- l'assioma della G diventa il mio stato iniziale;
- i simboli T diventano stati finali;
- tutte le produzioni vanno convertite in archi.
Non è sempre banale, tuttavia, convertire le grammatiche regolari in automa. Abbiamo visto che ci sono grammatiche regolari destre e sinistre, e noi vedremo - per ora - solo la conversione da grammatiche regolari destre. Le regole di conversione sono le seguenti:
- X::=aA diventa X ->a A
- X::=a diventa X ->a Z
- X::=ε diventa X ->ε Z
La scrittura X ->a A mi dice che vado dallo stato X allo stato A tramite un arco etichettato con a.
Non s'era detto che le grammatiche non amano le produzioni con la ε? È vero. E allora questa che cosa ci fa qui? BOH!
Torna alla pagina di Traduttori